
Aprender Linux é uma das habilidades mais valiosas na indústria de tecnologia. Pode ajudá-lo a realizar tarefas com mais rapidez e eficiência. Muitos dos servidores e supercomputadores mais poderosos do mundo rodam em Linux.
Ao mesmo tempo em que fortalece você em sua função atual, aprender Linux também pode ajudar na transição para outras carreiras de tecnologia, como DevOps, segurança cibernética e computação em nuvem.
Neste manual, você aprenderá os conceitos básicos da linha de comando do Linux e, em seguida, passará para tópicos mais avançados, como scripts de shell e administração de sistemas. Seja você iniciante no Linux ou usuário há anos, este livro tem algo para você.
Nota importante: Todos os exemplos deste livro são demonstrados no Ubuntu 22.04.2 LTS (Jammy Jellyfish). A maioria das ferramentas de linha de comando são mais ou menos iguais em outras distribuições. No entanto, alguns aplicativos e comandos de interface gráfica podem ser diferentes se você estiver trabalhando em outra distribuição Linux.
Índice
-
Parte 1: Introdução ao Linux
- 1.1. Introdução ao Linux
-
Parte 2: Introdução ao Bash Shell e aos Comandos do Sistema
-
2.1. Introdução ao shell Bash
-
2.2. Estrutura de Comando
-
2.3. Comandos Bash e Atalhos de Teclado
-
2.4. Identificando-se: O
whoamiComando
-
-
Parte 3: Compreendendo seu sistema Linux
- 3.1. Descobrindo seu sistema operacional e especificações
-
Parte 4: Gerenciando arquivos pela linha de comando
-
4.1. A Hierarquia do Sistema de Arquivos Linux
-
4.2. Navegando no sistema de arquivos Linux
-
4.3. Gerenciando Arquivos e Diretórios
-
4.5. Comandos básicos para visualização de arquivos
-
-
Parte 5: Noções básicas de edição de texto no Linux
-
5.1. Dominando o Vim: O Guia Completo
-
5.2. Dominando o Nano
-
-
Parte 6: Script Bash
-
6.1. Definição de script Bash
-
6.2. Vantagens do script Bash
-
6.3. Visão geral do Bash Shell e da Interface de Linha de Comando
-
6.4. Como criar e executar scripts Bash
-
6.5. Noções básicas de script Bash
-
-
Parte 7: Gerenciando Pacotes de Software no Linux
-
7.1. Pacotes e Gerenciamento de Pacotes
-
7.2. Instalando um pacote via linha de comando
-
7.3. Instalando um pacote por meio de um método gráfico avançado – Synaptic
-
7.4. Instalando pacotes baixados de um site
-
-
Parte 8: Tópicos avançados sobre Linux
-
8.1. Gerenciamento de usuários
-
8.2 Conexão com servidores remotos via SSH
-
8.3. Análise e Análise de Logs Avançadas
-
8.4. Gerenciando Processos Linux via Linha de Comando
-
8.5. Fluxos de entrada e saída padrão no Linux
-
8.6 Automação no Linux – Automatize tarefas com Cron Jobs
-
8.7. Noções básicas de rede Linux
-
8.8. Solução de problemas do Linux: ferramentas e técnicas
-
8.9. Estratégia geral de solução de problemas para servidores
-
8.10 Diagnosticando problemas de hardware
-
-
Conclusão
Parte 1: Introdução ao Linux
1.1. Introdução ao Linux
O que é Linux?
Linux é um sistema operacional de código aberto baseado no sistema operacional Unix. Foi criado por Linus Torvalds em 1991.
Código aberto significa que o código-fonte do sistema operacional está disponível ao público. Isso permite que qualquer pessoa modifique o código original, personalize e distribua o novo sistema operacional para usuários em potencial.
Por que você deve aprender sobre Linux?
No cenário atual de data centers, o Linux e o Microsoft Windows se destacam como os principais concorrentes, com o Linux tendo uma participação importante.
Aqui estão vários motivos convincentes para aprender Linux:
-
Dada a prevalência da hospedagem Linux, há uma grande chance de seu aplicativo ser hospedado em Linux. Portanto, aprender Linux como desenvolvedor se torna cada vez mais valioso.
-
Como a computação em nuvem está se tornando normal, há grandes chances de que suas instâncias de nuvem dependam do Linux.
-
O Linux serve como base para muitos sistemas operacionais para a Internet das Coisas (IoT) e aplicativos móveis.
-
Em TI, há muitas oportunidades para aqueles que estão no Linux.
O que significa que o Linux é um sistema operacional de código aberto?
Primeiro, o que é código aberto? Software de código aberto é aquele cujo código-fonte é de livre acesso, permitindo que qualquer pessoa o utilize, modifique e distribua.
Sempre que um código-fonte for criado, ele será automaticamente considerado protegido por direitos autorais, e sua distribuição é registrada pelos detentores dos direitos autorais por meio de licenças de software.
Ao contrário do código aberto, o proprietário do software ou de código fechado restringe o acesso ao seu código-fonte. Somente os criadores podem visualizá-lo, modificá-lo ou distribuí-lo.
O Linux é essencialmente de código aberto, o que significa que seu código-fonte está disponível gratuitamente. Qualquer pessoa pode visualizá-lo, modificá-lo e distribuí-lo. Desenvolvedores de qualquer lugar do mundo podem contribuir para seu aprimoramento. Isso estabelece a base da colaboração, um aspecto importante do software de código aberto.
Essa abordagem colaborativa levou a uma ampla adoção do Linux em servidores, desktops, sistemas embarcados e dispositivos móveis.
O aspecto mais interessante do Linux ser de código aberto é que qualquer um pode adaptar o sistema operacional às suas necessidades específicas sem ser restrito por limitações próprias.
O Chrome OS usado pelos Chromebooks é baseado no Linux. O Android, que equipa muitos smartphones no mundo todo, também é baseado no Linux.
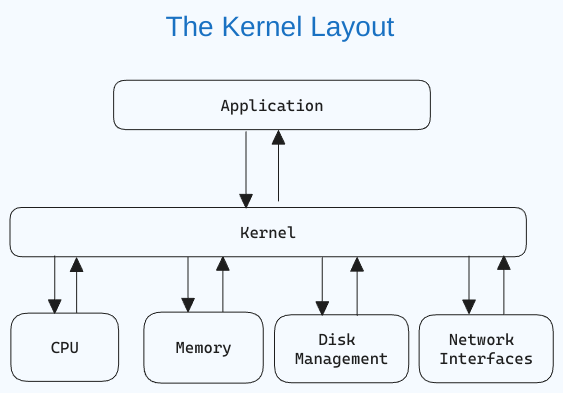
O que é um kernel Linux?
O kernel é o componente central de um sistema operacional que gerencia o computador e suas operações de hardware. Ele gerencia as transações de memória e o tempo de CPU.
O kernel atua como uma ponte entre os aplicativos e o processamento de dados no nível de hardware usando comunicação entre processos e chamadas de sistema.
O kernel é carregado na memória primeiro quando um sistema operacional é inicializado e permanece lá até o sistema ser desligado. Ele é responsável por tarefas como gerenciamento de disco, gerenciamento de tarefas e gerenciamento de memória.
Se você está curioso sobre a aparência do kernel do Linux, aqui está o link do GitHub.
O que é uma distribuição Linux?
A esta altura, você já sabe que pode reutilizar o código do kernel Linux, modificá-lo e criar um novo kernel. Você ainda pode combinar diferentes veículos e softwares para criar um sistema operacional completamente novo.
Uma distribuição Linux ou distro é uma versão do sistema operacional Linux que inclui o kernel Linux, importados do sistema e outros softwares. Sendo de código aberto, uma distribuição Linux é um esforço colaborativo que envolve diversas comunidades independentes de desenvolvimento de código aberto.
O que significa que uma distribuição é derivada? Quando se diz que uma distribuição é "derivada" de outra, a distribuição mais recente é construída sobre a base ou fundamento da distribuição original. Essa derivação pode incluir o uso do mesmo sistema de gerenciamento de pacotes (falaremos mais sobre isso posteriormente), a mesma versão do kernel e, às vezes, as mesmas ferramentas de configuração.
Hoje, há milhares de distribuições Linux para escolher, oferecendo diferentes objetivos e critérios para selecionar e dar suporte ao software fornecido por sua distribuição.
As distribuições variam de uma para outra, mas geralmente têm várias características comuns:
-
Uma distribuição consiste em um kernel Linux.
-
Ele suporta programas de espaço do usuário.
-
Uma distribuição pode ser pequena e propositalmente única ou incluir milhares de programas de código aberto.
-
Alguns meios de instalação e atualização da distribuição e seus componentes devem ser fornecidos.
Se você visualizar a Linha do Tempo das Distribuições Linux , verá duas distros principais: Slackware e Debian. Diversas distribuições são derivadas delas. Por exemplo, Ubuntu e Kali são derivados do Debian.
Quais são as vantagens da derivação? Existem várias vantagens na derivação. As distribuições derivadas podem beneficiar a estabilidade, a segurança e os grandes repositórios de software da distribuição original.
Ao desenvolver sobre uma base existente, os desenvolvedores concentram seu foco e se esforçam especificamente em recursos especializados da nova distribuição. Os usuários de distribuições derivadas podem se beneficiar da documentação, do suporte da comunidade e dos recursos já disponíveis para a distribuição original.
Algumas distribuições Linux populares são:
-
Ubuntu : Uma das distribuições Linux mais utilizadas e populares. É fácil de usar e recomendado para iniciantes. Saiba mais sobre o Ubuntu aqui .
-
Linux Mint : Baseado no Ubuntu, o Linux Mint oferece uma experiência amigável ao usuário com foco em suporte multimídia. Saiba mais sobre o Linux Mint aqui .
-
Arch Linux : Popular entre usuários experientes, o Arch é uma distribuição leve e flexível, externa para usuários que preferem uma abordagem "faça você mesmo". Saiba mais sobre o Arch Linux aqui .
-
Manjaro : Baseado no Arch Linux, o Manjaro oferece uma experiência amigável com software pré-instalado e ferramentas simples de gerenciamento do sistema. Saiba mais sobre o Manjaro aqui .
-
Kali Linux : O Kali Linux oferece um conjunto abrangente de ferramentas de segurança e é focado principalmente em segurança cibernética e hacking. Saiba mais sobre o Kali Linux aqui .
Como instalar e acessar o Linux
A melhor maneira de aprender é aplicar os conceitos à medida que avança. Nesta seção, aprenderemos como instalar o Linux em sua máquina para que você possa acompanhar. Você também aprenderá como acessar o Linux em uma máquina Windows.
Recomendamos que você siga qualquer um dos métodos indicados nesta seção para obter acesso ao Linux, então você pode acompanhar.
Instalar o Linux como sistema operacional principal
Instalar o Linux como sistema operacional principal é a maneira mais eficiente de usar o Linux, pois você pode usar todo o poder da sua máquina.
Nesta seção, você aprenderá a instalar o Ubuntu, uma das distribuições Linux mais populares. Deixei de fora outras distribuições por enquanto, pois quero manter as coisas simples. Você sempre pode explorar outras distribuições quando se sentir confortável com o Ubuntu.
-
Passo 1 – Baixe o iso do Ubuntu: Acesse o site oficial e baixe o arquivo iso. Selecione uma versão estável com o nome "LTS". LTS significa Suporte de Longo Prazo, o que significa que você pode obter atualizações gratuitas de segurança e manutenção por um longo período (geralmente 5 anos).
-
Passo 2 – Crie um pendrive inicializável: Existem diversos softwares que permitem criar um pendrive inicializável. Recomendo usar o Rufus, pois é bem fácil de usar. Você pode baixá-lo aqui .
-
Passo 3 – Inicialize a partir do pendrive: Assim que seu pendrive inicializável estiver pronto, insira-o e inicialize a partir dele. O menu de inicialização depende do seu laptop. Você pode pesquisar no Google o menu de inicialização para o modelo do seu laptop.
-
Passo 4 – Siga as instruções. Assim que o processo de inicialização começar, selecione
try or install ubuntu.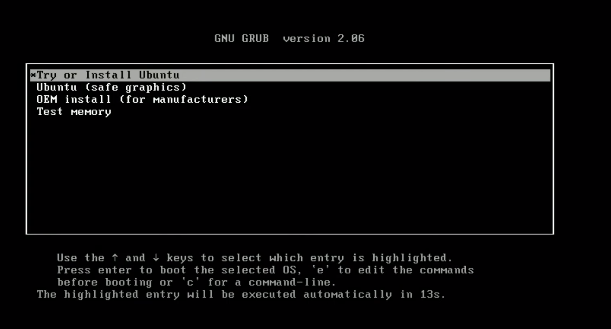
O processo avança em algum tempo. Assim que a interface gráfica aparecer, você poderá selecionar o idioma e o layout do teclado e continuar. Digite seu login e nome de usuário. Anote as credenciais, pois você precisa delas para fazer login no sistema e acessar todos os privilégios. Aguarde a conclusão da instalação.
-
Passo 5 – Reiniciar: Clique em reiniciar agora e remover o pen drive.
-
Etapa 6 – Login: Faça login com as credenciais inseridas anteriormente.
Pronto! Agora você pode instalar aplicativos e personalizar sua área de trabalho.
Para instalação avançada, você pode explorar os seguintes tópicos:
-
Particionamento de disco.
-
Configurando troca de memória para ativar a hibernação.
Acessando o terminal
Uma parte importante deste manual é aprender sobre o terminal, onde você executará todos os comandos e verá uma mágica acontecer. Você pode procurar o terminal pressionando a tecla "windows" e escrevendo "terminal". Você pode consertar o Terminal no dock, onde outros aplicativos estão localizados, para facilitar o acesso.
💡 O atalho para abrir o terminal é
ctrl+alt+t
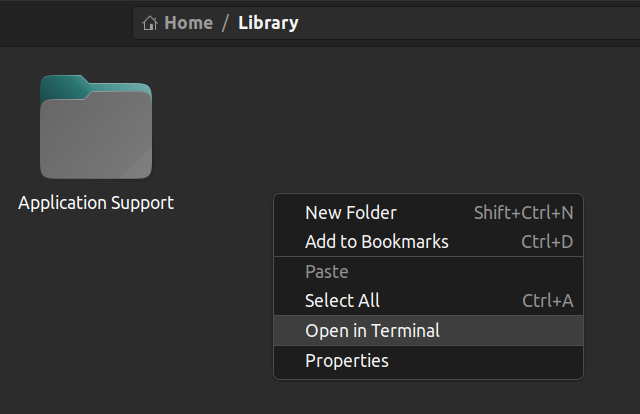
Você também pode abrir o terminal de dentro de uma pasta. Clique com o botão direito do mouse onde você está e clique em "Abrir no Terminal". Isso abrirá o terminal no mesmo caminho.
Como usar Linux em uma máquina Windows
Às vezes, você pode precisar executar Linux e Windows simultaneamente. Felizmente, existem algumas maneiras de aproveitar o melhor dos dois mundos sem precisar de computadores diferentes para cada sistema operacional.
Nesta seção, você explorará algumas maneiras de usar o Linux em uma máquina Windows. Algumas delas são baseadas no navegador ou na nuvem e não desativam a instalação do sistema operacional antes de serem usadas.
Opção 1: "Dual-boot" Linux + Windows Com dual boot, você pode instalar o Linux junto com o Windows no seu computador, permitindo que você escolha qual sistema operacional usar na inicialização.
Isso requer particionar seu disco rígido e instalar o Linux em uma partição separada. Com essa abordagem, você só pode usar um sistema operacional por vez.
Opção 2: usar o Subsistema Windows para Linux (WSL) O Subsistema Windows para Linux fornece uma camada de compatibilidade que permite executar opções binárias do Linux nativamente no Windows.
Usar o WSL tem algumas vantagens. A configuração do WSL é simples e rápida. É leve em comparação com VMs, onde você precisa alocar recursos da máquina host. Você não precisa instalar nenhum ISO ou imagem de disco virtual para máquinas Linux, que tendem a ter arquivos pesados. Você pode usar Windows e Linux simultaneamente.
Como instalar o WSL2
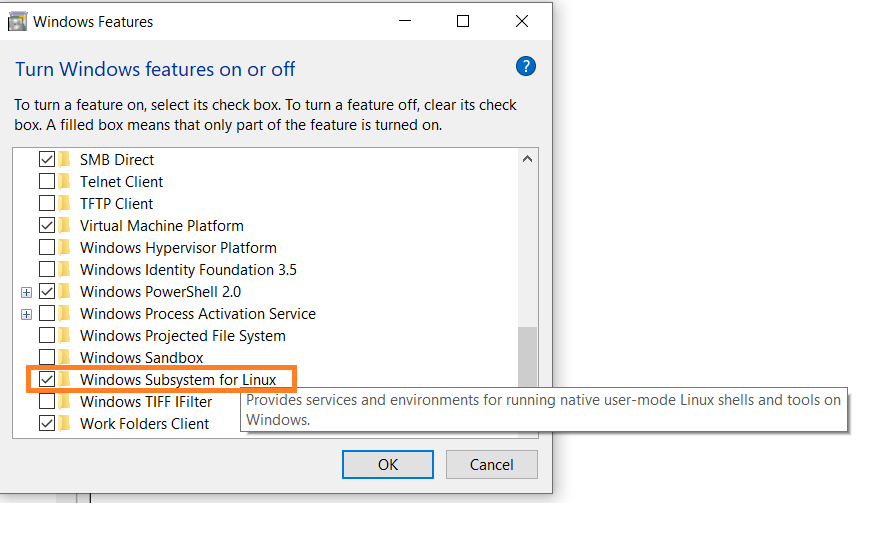
Primeiro, ative a opção Subsistema Windows para Linux nas configurações.
-
Vá em Iniciar. Procure por "Ativar ou desativar recursos do Windows".
-
Marque a opção "Subsistema Windows para Linux" caso ainda não esteja.
-
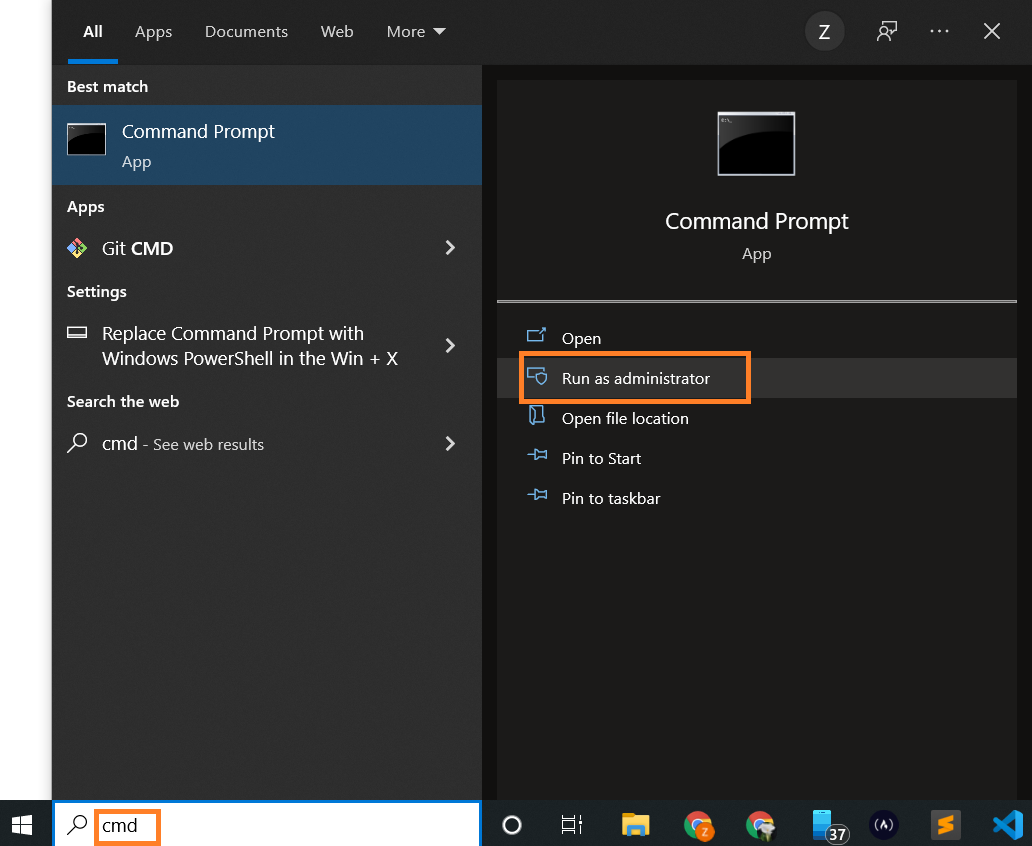
Em seguida, abra o prompt de comando e forneça os comandos de instalação.
-
Abra o Prompt de Comando como administrador:
-
Execute o comando abaixo:
wsl --install
Isto é a saída:
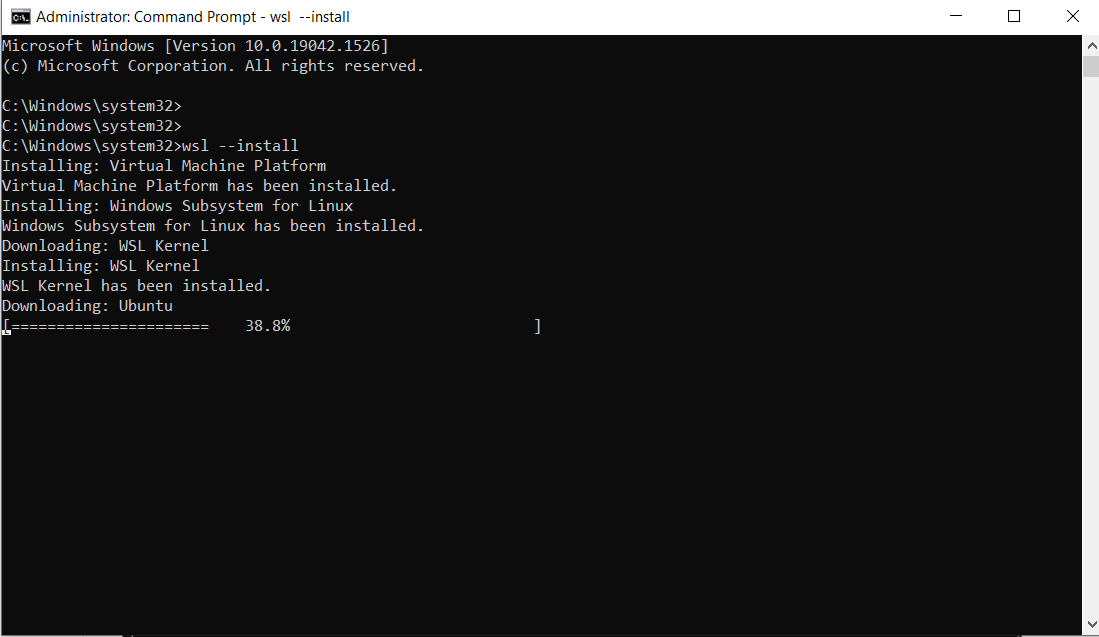
Observação: por padrão, o Ubuntu será instalado.
- Após a conclusão da instalação, você precisará reiniciar seu computador Windows. Portanto, reinicie o seu computador Windows.
Após a reinicialização, você poderá ver uma janela como esta:
Quando a instalação do Ubuntu estiver concluída, você será solicitado a digitar seu nome de usuário e senha.
E pronto! Você está pronto para usar o Ubuntu.
Inicie o Ubuntu pesquisando no menu iniciar.
E aqui temos sua instância do Ubuntu iniciada.
Opção 3: Usar uma máquina virtual (VM)
Uma máquina virtual (VM) é uma emulação de software de um sistema computacional físico. Ela permite executar vários sistemas operacionais e aplicativos em uma única máquina física simultaneamente.
Você pode usar um software de virtualização como o Oracle VirtualBox ou o VMware para criar uma máquina virtual executando Linux em seu ambiente Windows. Isso permite que você execute o Linux como um sistema operacional convidado junto com o Windows.
O software de VM oferece opções para alocar e gerenciar recursos de hardware para cada VM, incluindo núcleos de CPU, memória, espaço em disco e largura de banda de rede. Você pode ajustar essas alocações com base nos requisitos dos sistemas operacionais e aplicativos solicitados.
Aqui estão algumas das opções comuns para virtualização:
Opção 4: Utilizar uma solução baseada no navegador
As soluções baseadas no navegador são particularmente úteis para testes rápidos, aprendizado ou acesso a ambientes Linux a partir de dispositivos que não tenham o Linux instalado.
Você pode usar editores de código online ou terminais web para acessar o Linux. Observe que, nesses casos, você geralmente não tem privilégios totais de administração.
Editores de código online
Editores de código online oferecem editores com terminais Linux integrados. Embora seu objetivo principal seja o planejado, você também pode usar o terminal Linux para executar comandos e tarefas.
Replit é um exemplo de editor de código online, onde você pode escrever seu código e acessar o shell do Linux ao mesmo tempo.
Terminais Linux baseados na Web:
Os terminais Linux online permitem que você acesse uma interface de linha de comando do Linux diretamente do seu navegador. Esses terminais fornecem uma interface web para um shell Linux, permitindo que você execute comandos e trabalhe com importados Linux.
Um exemplo disso é o JSLinux . A captura de tela abaixo mostra um ambiente Linux pronto para uso:
Opção 5: Usar uma solução baseada em nuvem
Ao executar o Linux diretamente em sua máquina Windows, você pode considerar usar ambientes Linux baseados em nuvem ou servidores virtuais privados (VPS) para acessar e trabalhar com o Linux remotamente.
Serviços como Amazon EC2, Microsoft Azure ou DigitalOcean oferecem instâncias Linux nas quais você pode se conectar a partir de seu computador Windows. Observe que alguns desses serviços oferecem níveis gratuitos, mas geralmente não são gratuitos a longo prazo.
Parte 2: Introdução ao Bash Shell e aos Comandos do Sistema
2.1. Introdução ao shell Bash
Introdução ao shell bash
A linha de comando do Linux é fornecida por um programa chamado shell. Ao longo dos anos, o programa shell evoluiu para atender a diversas opções.
Usuários diferentes podem ser configurados para usar shells diferentes. No entanto, a maioria dos usuários prefere manter o shell padrão atual. O shell padrão para muitas distribuições Linux é o GNU Bourne-Again Shell ( bash). O Bash é substituído pelo Bourne Shell ( sh).
Para descobrir seu shell atual, abra seu terminal e digite o seguinte comando:
echo $SHELL
Análise de comando:
-
O
echocomando é usado para imprimir no terminal. -
Esta
$SHELLé uma variável especial que contém o nome do shell atual.
Na minha configuração, a saída é /bin/bash. Isso significa que estou usando o shell bash.
# output
echo $SHELL
/bin/bash
O Bash é muito poderoso, pois pode simplificar certas operações que são difíceis de realizar com eficiência com uma GUI (ou Interface Gráfica do Usuário). Lembre-se de que a maioria dos servidores não possui uma GUI, e é melhor aprender a usar os recursos de uma interface de linha de comando (CLI).
Terminal vs Shell
Os termos "terminal" e "shell" são frequentemente usados de forma intercambiável, mas se referem a partes diferentes da interface de linha de comando.
O terminal é a interface que você usa para interagir com o shell. O shell é o interpretador de comandos que processa e executa seus comandos. Você aprenderá mais sobre shells na Parte 6 do manual.
O que é um prompt?
Quando um shell é usado interativamente, ele exibe uma mensagem de alerta $ enquanto aguarda um comando do usuário. Isso é chamado de prompt do shell.
[username@host ~]$
Se o shell estiver sendo executado como root (você aprenderá mais sobre o usuário root mais tarde), o prompt será alterado para #.
[root@host ~]#
2.2. Estrutura de Comando
Um comando é um programa que executa uma operação específica. Após acessar o shell, você pode digitar qualquer comando após o $ sinal e ver a saída no terminal.
Geralmente, os comandos do Linux seguem esta sintaxe:
command [options] [arguments]
Aqui está a análise da sintaxe acima:
-
command: Este é o nome do comando que você deseja executar.ls(listar),cp(copiar) erm(remover) são comandos comuns do Linux. -
[options]: Opções, ou sinalizadores, geralmente precedidos por um hífen (-) ou hífen duplo (--), modificam o comportamento do comando. Elas podem alterar o funcionamento do comando. Por exemplo,ls -ausa a-aopção para exibir arquivos ocultos no diretório atual. -
[arguments]: Argumentos são as entradas para os comandos que os requerem. Podem ser nomes de arquivos, nomes de usuários ou outros dados sobre os quais o comando atuará. Por exemplo, no comandocat access.log,caté o comando eaccess.logé a entrada. Como resultado, ocatcomando exibe o conteúdo doaccess.logarquivo.
Opções e argumentos não são obrigatórios para todos os comandos. Alguns comandos podem ser executados sem opções ou argumentos, enquanto outros podem exigir um ou ambos para funcionar corretamente. Você pode sempre consultar o manual do comando para verificar as opções e argumentos que ele suporta.
💡 Dica: Você pode visualizar o manual de um comando usando o man comando.
Você pode acessar a página do manual ls com man ls, e ela se parecerá com isto:
As páginas de manual são uma maneira ótima e rápida de acessar a documentação. Recomendo fortemente consultar as páginas de manual dos comandos que você mais usa.
2.3. Comandos Bash e Atalhos de Teclado
Quando estiver no terminal, você pode acelerar suas tarefas usando atalhos.
Aqui estão alguns dos atalhos de terminal mais comuns:
| Operação | Atalho |
| Procure o comando anterior | Seta para cima |
| Ir para o início da palavra anterior | Ctrl+Seta para a esquerda |
| Limpar caracteres do cursor até o final da linha de comando | Ctrl+K |
| Comandos completos, nomes de arquivos e opções | Pressionando Tab |
| Vai para o início da linha de comando | Ctrl+A |
| Exibe a lista de comandos anteriores | história |
2.4. Identificando-se: O whoami Comando
Você pode obter o nome de usuário com o qual está conectado usando o whoami comando . Este comando é útil quando você está alternando entre diferentes usuários e deseja confirmar o usuário atual.
Logo após o $ sinal, digite whoami e pressione enter.
whoami
Este é o resultado que obtive.
zaira@zaira-ThinkPad:~$ whoami
zaira
Parte 3: Compreendendo seu sistema Linux
3.1. Descobrindo seu sistema operacional e especificações
Imprimir informações do sistema usando o uname comando
Você pode obter informações detalhadas do sistema a partir do uname comando.
Quando você fornece a -a opção, ele imprime todas as informações do sistema.
uname -a
# output
Linux zaira 6.5.0-21-generic #21~22.04.1-Ubuntu SMP PREEMPT_DYNAMIC Fri Feb 9 13:32:52 UTC 2 x86_64 x86_64 x86_64 GNU/Linux
Na saída acima,
-
Linux: Indica o sistema operacional. -
zaira: Representa o nome do host da máquina. -
6.5.0-21-generic #21~22.04.1-Ubuntu SMP PREEMPT_DYNAMIC Fri Feb 9 13:32:52 UTC 2: Fornece informações sobre a versão do kernel, data de compilação e alguns detalhes adicionais. -
x86_64 x86_64 x86_64: Indica a arquitetura do sistema. -
GNU/Linux: Representa o tipo de sistema operacional.
Encontre detalhes da arquitetura da CPU usando o lscpu comando
O lscpu comando no Linux é usado para exibir informações sobre a arquitetura da CPU. Quando executado lscpu no terminal, ele fornece detalhes como:
-
A arquitetura da CPU (por exemplo, x86_64)
-
Modo(s) de operação da CPU (por exemplo, 32 bits, 64 bits)
-
Ordem de bytes (por exemplo, Little Endian)
-
CPU(s) (número de CPUs) e assim por diante
Vamos experimentar:
lscpu
# output
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Address sizes: 48 bits physical, 48 bits virtual
Byte Order: Little Endian
CPU(s): 12
On-line CPU(s) list: 0-11
Vendor ID: AuthenticAMD
Model name: AMD Ryzen 5 5500U with Radeon Graphics
Thread(s) per core: 2
Core(s) per socket: 6
Socket(s): 1
Stepping: 1
CPU max MHz: 4056.0000
CPU min MHz: 400.0000
Foi muita informação, mas também foi útil! Lembre-se de que você sempre pode consultar as informações relevantes usando sinalizadores específicos. Consulte o manual de comandos com man lscpu.
Parte 4: Gerenciando arquivos pela linha de comando
4.1. A Hierarquia do Sistema de Arquivos Linux
Todos os arquivos no Linux são armazenados em um sistema de arquivos. Ele segue uma estrutura semelhante a uma árvore invertida, pois a raiz está na parte superior.
Este / é o diretório raiz e o ponto de partida do sistema de arquivos. O diretório raiz contém todos os outros diretórios e arquivos do sistema. O / caractere também serve como separador de diretório entre nomes de caminho. Por exemplo, /home/alice forma um caminho completo.
A imagem abaixo mostra a hierarquia completa do sistema de arquivos. Cada diretório atende a uma finalidade específica.
Observe que esta não é uma lista exaustiva e diferentes distribuições podem ter configurações diferentes.
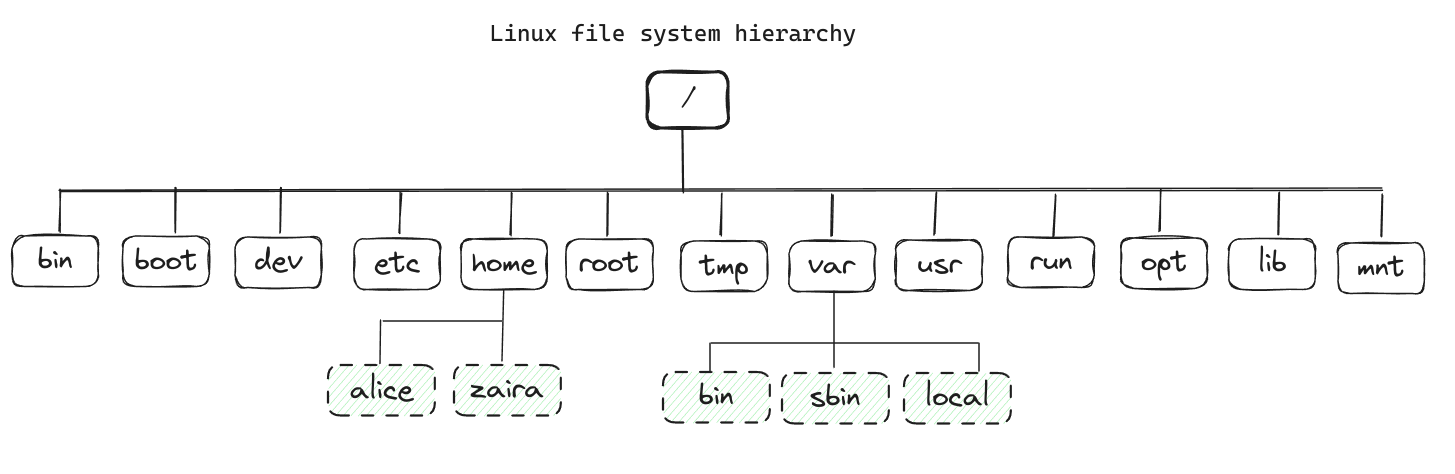
Aqui está uma tabela que mostra a finalidade de cada diretório:
| Localização | Propósito |
| /bin | Binários de comando essenciais |
| /bota | Arquivos estáticos do carregador de boot, necessários para iniciar o processo de inicialização. |
| /etc | Configuração do sistema específica do host |
| /lar | Diretórios pessoais do usuário |
| /raiz | Diretório inicial para o usuário root administrativo |
| /lib | Bibliotecas compartilhadas essenciais e módulos do kernel |
| /mnt | Ponto de montagem para montar um sistema de arquivos temporariamente |
| /optar | Pacotes de software de aplicativos complementares |
| /usr | Software instalado e bibliotecas compartilhadas |
| /var | Dados variáveis que também são persistentes entre inicializações |
| /tmp | Arquivos temporários acessíveis a todos os usuários |
💡 Dica: Você pode aprender mais sobre o sistema de arquivos usando o man hier comando.
Você pode verificar seu sistema de arquivos usando o tree -d -L 1 comando. Você pode modificar o -L sinalizador para alterar a profundidade da árvore.
tree -d -L 1
# output
.
├── bin -> usr/bin
├── boot
├── cdrom
├── data
├── dev
├── etc
├── home
├── lib -> usr/lib
├── lib32 -> usr/lib32
├── lib64 -> usr/lib64
├── libx32 -> usr/libx32
├── lost+found
├── media
├── mnt
├── opt
├── proc
├── root
├── run
├── sbin -> usr/sbin
├── snap
├── srv
├── sys
├── tmp
├── usr
└── var
25 directories
Esta lista não é exaustiva e diferentes distribuições e sistemas podem ser configurados de forma diferente.
4.2. Navegando no sistema de arquivos Linux
Caminho absoluto vs caminho relativo
O caminho absoluto é o caminho completo do diretório raiz até o arquivo ou diretório. Ele sempre começa com /. Por exemplo, /home/john/documents.
O caminho relativo, por outro lado, é o caminho do diretório atual até o arquivo ou diretório de destino. Ele não começa com /. Por exemplo, documents/work/project.
Localizando seu diretório atual usando o pwd comando
É fácil se perder no sistema de arquivos do Linux, especialmente se você não tem familiaridade com a linha de comando. Você pode localizar seu diretório atual usando o pwd comando .
Aqui está um exemplo:
pwd
# output
/home/zaira/scripts/python/free-mem.py
Alterando diretórios usando o cd comando
O comando para alterar diretórios é cd e significa "change directory" (mudar diretório). Você pode usar o cd comando para navegar para um diretório diferente.
Você pode usar um caminho relativo ou um caminho absoluto.
Por exemplo, se você quiser navegar pela estrutura de arquivo abaixo (seguindo as linhas vermelhas):
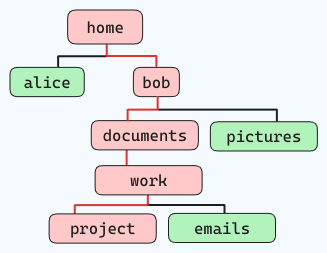
e você estiver em "casa", o comando seria assim:
cd home/bob/documents/work/project
Alguns outros cd atalhos comumente usados são:
| Comando | Descrição |
cd .. |
Voltar um diretório |
cd ../.. |
Voltar dois diretórios |
cd ou cd ~ |
Vá para o diretório inicial |
cd - |
Vá para o caminho anterior |
4.3. Gerenciando Arquivos e Diretórios
Ao trabalhar com arquivos e diretórios, você pode querer copiar, mover, remover e criar novos arquivos e diretórios. Aqui estão alguns comandos que podem ajudar com isso.
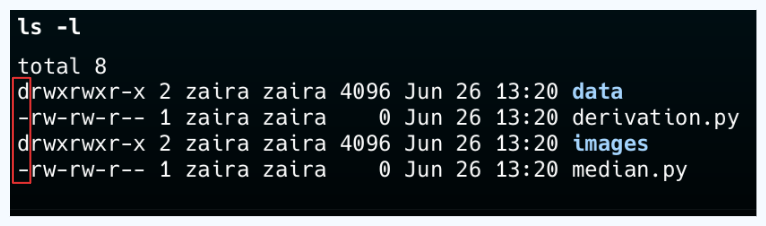
💡 Dica: Você pode diferenciar um arquivo de uma pasta observando a primeira letra na saída de ls -l. A '-' representa um arquivo e a 'd' representa uma pasta.
Criando novos diretórios usando o mkdir comando
Você pode criar um diretório vazio usando o mkdir comando.
# creates an empty directory named "foo" in the current folder
mkdir foo
Você também pode criar diretórios recursivamente usando a -p opção.
mkdir -p tools/index/helper-scripts
# output of tree
.
└── tools
└── index
└── helper-scripts
3 directories, 0 files
Criando novos arquivos usando o touch comando
O touch comando cria um arquivo vazio. Você pode usá-lo assim:
# creates empty file "file.txt" in the current folder
touch file.txt
Os nomes dos arquivos podem ser encadeados se você quiser criar vários arquivos em um único comando.
# creates empty files "file1.txt", "file2.txt", and "file3.txt" in the current folder
touch file1.txt file2.txt file3.txt
Removendo arquivos e diretórios usando o comando rm and rmdir
Você pode usar o rm comando para remover arquivos e diretórios não vazios.
| Comando | Descrição |
rm file.txt |
Remove o arquivo file.txt |
rm -r directory |
Remove o diretório directory e seu conteúdo |
rm -f file.txt |
Remove o arquivo file.txt sem solicitar confirmação |
rmdir diretório |
Remove um diretório vazio |
🛑 Observe que você deve usar o -f sinalizador com cautela, pois não será perguntado antes de excluir um arquivo. Além disso, tenha cuidado ao executar rm comandos na root pasta, pois isso pode resultar na exclusão de arquivos importantes do sistema.
Copiando arquivos usando o cp comando
Para copiar arquivos no Linux, use o cp comando.
- Sintaxe para copiar arquivos:
cp source_file destination_of_file
Este comando copia um arquivo chamado file1.txt para um novo arquivo /home/adam/logs.
cp file1.txt /home/adam/logs
O cp comando também cria uma cópia de um arquivo com o nome fornecido.
Este comando copia um arquivo nomeado file1.txt para outro arquivo nomeado file2.txt na mesma pasta.
cp file1.txt file2.txt
Mover e renomear arquivos e pastas usando o mvcomando
O mvcomando é usado para mover arquivos e pastas de um diretório para outro.
Sintaxe para mover arquivos:mv source_file destination_directory
Exemplo: mover um arquivo chamado file1.txtpara um diretório chamado backup:
mv file1.txt backup/
Para mover um diretório e seu conteúdo:
mv dir1/ backup/
Renomear arquivos e pastas no Linux também é feito com o mvcomando.
Sintaxe para renomear arquivos:mv old_name new_name
Exemplo: Renomear um arquivo de file1.txtpara file2.txt:
mv file1.txt file2.txt
Renomear um diretório dir1para dir2:
mv dir1 dir2
4.4. Localizando arquivos e pastas usando o findcomando
O findcomando permite que você pesquise com eficiência arquivos, pastas e dispositivos de caracteres e blocos.
Abaixo está a sintaxe básica do findcomando:
find /path/ -type f -name file-to-search
Onde,
-
/pathé o caminho onde se espera que o arquivo seja encontrado. Este é o ponto de partida para a busca de arquivos. O caminho também pode ser/ou ,.que representa a raiz e o diretório atual, respectivamente. -
-typerepresenta os descritores do arquivo. Eles podem ser qualquer um dos seguintes:f– Arquivo regular , como arquivos de texto, imagens e arquivos ocultos.d– Diretório . Estas são as pastas em consideração.l– Link simbólico . Links simbólicos apontam para arquivos e são semelhantes aos atalhos.c– Dispositivos de caracteres . Os arquivos usados para acessar dispositivos de caracteres são chamados de arquivos de dispositivos de caracteres. Os drivers se comunicam com dispositivos de caracteres enviando e recebendo caracteres únicos (bytes, octetos). Exemplos incluem teclados, placas de som e mouse.b– Dispositivos de bloco . Os arquivos usados para acessar dispositivos de bloco são chamados de arquivos de dispositivos de bloco. Os drivers se comunicam com dispositivos de envio de blocos e recebimento de blocos inteiros de dados. Exemplos incluem USB e CD-ROM -
-nameé o nome do tipo de arquivo que você deseja pesquisar.
Como pesquisar arquivos por nome ou extensão
Suponha que você precise encontrar arquivos que contenham "estilo" no nome. Usaremos este comando:
find . -type f -name "style*"
#output
./style.css
./styles.css
Agora, queremos encontrar arquivos com uma extensão específica, como .html. Modificaremos o comando assim:
find . -type f -name "*.html"
# output
./services.html
./blob.html
./index.html
Como pesquisar arquivos ocultos
Um ponto no início do nome do arquivo representa arquivos ocultos. Normalmente, eles ficam ocultos, mas podem ser visualizados ls -ano diretório atual.
Podemos modificar o findcomando conforme mostrado abaixo para procurar arquivos ocultos:
find . -type f -name ".*"
Listar e encontrar arquivos ocultos
ls -la
# folder contents
total 5
drwxrwxr-x 2 zaira zaira 4096 Mar 26 14:17 .
drwxr-x--- 61 zaira zaira 4096 Mar 26 14:12 ..
-rw-rw-r-- 1 zaira zaira 0 Mar 26 14:17 .bash_history
-rw-rw-r-- 1 zaira zaira 0 Mar 26 14:17 .bash_logout
-rw-rw-r-- 1 zaira zaira 0 Mar 26 14:17 .bashrc
find . -type f -name ".*"
# find output
./.bash_logout
./.bashrc
./.bash_history
Acima você pode ver uma lista de arquivos ocultos no meu diretório inicial.
Como pesquisar arquivos de log e arquivos de configuração
Os arquivos de log geralmente têm extensão .log, e podemos encontrá-los assim:
find . -type f -name "*.log"
Da mesma forma, podemos procurar por arquivos de configuração como este:
find . -type f -name "*.conf"
Como pesquisar outros arquivos por tipo
Podemos pesquisar arquivos de blocos de caracteres cfornecidos -type:
find / -type c
Da mesma forma, podemos encontrar arquivos de blocos de dispositivos usando b:
find / -type b
Como pesquisar diretórios
No exemplo abaixo, encontramos as pastas usando o -type dsinalizador.
ls -l
# list folder contents
drwxrwxr-x 2 zaira zaira 4096 Mar 26 14:22 hosts
-rw-rw-r-- 1 zaira zaira 0 Mar 26 14:23 hosts.txt
drwxrwxr-x 2 zaira zaira 4096 Mar 26 14:22 images
drwxrwxr-x 2 zaira zaira 4096 Mar 26 14:23 style
drwxrwxr-x 2 zaira zaira 4096 Mar 26 14:22 webp
find . -type d
# find directory output
.
./webp
./images
./style
./hosts
Como pesquisar arquivos por tamanho
Um uso extremamente útil do findcomando é listar arquivos com base em um tamanho específico.
find / -size +250M
Aqui listamos arquivos cujo tamanho excede 250MB.
Outras unidades de transmissão:
-
G: GigaBytes. -
M: MegaBytes. -
K: Quilobytes -
c: bytes.
Basta substituir pela unidade relevante.
find <directory> -type f -size +N<Unit Type>
Como pesquisar arquivos por hora de modificação
Ao usar o -mtimesinalizador, você pode filtrar arquivos e pastas com base no local de modificação.
find /path -name "*.txt" -mtime -10
Por exemplo,
-
-mtime +10 significa que você está procurando um arquivo modificado há 10 dias.
-
-mtime -10 significa menos de 10 dias.
-
-mtime 10 Se você pular + ou – significa exatamente 10 dias.
4.5. Comandos básicos para visualização de arquivos
Concatenar e exibir arquivos usando o catcomando
O catcomando no Linux é usado para exibir o conteúdo de um arquivo. Também pode ser usado para concatenar arquivos e criar novos arquivos.
Aqui está a sintaxe básica do catcomando:
cat [options] [file]
A maneira mais simples de usar caté sem opções ou argumentos. Isso exibirá o conteúdo do arquivo no terminal.
Por exemplo, se você quiser visualizar o conteúdo de um arquivo chamado file.txt, você pode usar o seguinte comando:
cat file.txt
Isso exibirá todo o conteúdo do arquivo no terminal de uma só vez.
Visualização interativa de arquivos de texto usando lessemore
Exibe cato arquivo inteiro de uma só vez lesse morepermite visualizar o conteúdo de um arquivo interativamente. Isso é útil quando você deseja navegar por um arquivo grande ou pesquisar por conteúdo específico.
A sintaxe do lesscomando é:
less [options] [file]
O morecomando é semelhante, lessmas possui menos recursos. Ele é usado para exibir o conteúdo de um arquivo em uma tela por vez.
A sintaxe do morecomando é:
more [options] [file]
Para ambos os comandos, você pode usar uma tecla spacebarpara rolar uma página para baixo, uma Entertecla para rolar uma linha para baixo e uma qtecla para sair do visualizador.
Para retroceder você pode usar a btecla , e para avançar você pode usar a ftecla .
Exibindo a última parte dos arquivos usandotail
Às vezes, você pode precisar visualizar apenas as últimas linhas de um arquivo em vez de todo o arquivo. O tailcomando no Linux é usado para exibir a última parte de um arquivo.
Por exemplo, tail file.txtserão exibidas as últimas 10 linhas do arquivo file.txt por padrão.
Se quiser escolher um número diferente de linhas, você pode usar a -nopção seguida do número de linhas que deseja exibir.
# Display the last 50 lines of the file file.txt
tail -n 50 file.txt
💡 Dica: Outro uso do tailé o seu acompanhamento ( -f ). Esta opção permite visualizar o conteúdo de um arquivo enquanto ele é gravado. Este é um recurso útil para visualizar e monitorar arquivos de log em tempo real.
Exibindo o início dos arquivos usandohead
Assim como tailexibe a última parte de um arquivo, você pode usar o headcomando no Linux para exibir o início de um arquivo.
Por exemplo, head file.txtserão exibidas as primeiras 10 linhas do arquivo file.txtpor padrão.
Para alterar o número de linhas exibidas, você pode usar a -nopção seguida do número de linhas que deseja exibir.
Contagem de palavras, linhas e caracteres usandowc
Você pode contar palavras, linhas e caracteres em um arquivo usando o wccomando.
Por exemplo, a execução wc syslog.logme deu a seguinte saída:
1669 9623 64367 syslog.log
Na saída acima,
-
1669representa o número de linhas no arquivosyslog.log. -
9623representa o número de palavras no arquivosyslog.log. -
64367representa o número de caracteres no arquivosyslog.log.
Então, o comando wc syslog.logcontorno 1669linhas, 9623palavras e 64367caracteres no arquivo syslog.log.
Comparando arquivos linha por linha usandodiff
Comparar e encontrar diferenças entre dois arquivos é uma tarefa comum no Linux. Você pode comparar dois arquivos diretamente na linha de comando usando o diffcomando .
A sintaxe básica do diffcomando é:
diff [options] file1 file2
Aqui dois arquivos, hello.pye also-hello.py, que compararemos usando o diffcomando:
# contents of hello.py
def greet(name):
return f"Hello, {name}!"
user = input("Enter your name: ")
print(greet(user))
# contents of also-hello.py
more also-hello.py
def greet(name):
return fHello, {name}!
user = input(Enter your name: )
print(greet(user))
print("Nice to meet you")
- Verifique se os arquivos são iguais ou não
diff -q hello.py also-hello.py
# Output
Files hello.py and also-hello.py differ
- Veja como os arquivos próximos. Para isso, você pode usar o
-usinalizador para ver uma saída unificada:
diff -u hello.py also-hello.py
--- hello.py 2024-05-24 18:31:29.891690478 +0500
+++ also-hello.py 2024-05-24 18:32:17.207921795 +0500
@@ -3,4 +3,5 @@
user = input(Enter your name: )
print(greet(user))
+print("Nice to meet you")
Na saída acima:
-
--- hello.py 2024-05-24 18:31:29.891690478 +0500indica o arquivo que está sendo comparado e seu registro de dados e hora. -
+++ also-hello.py 2024-05-24 18:32:17.207921795 +0500indica o outro arquivo que está sendo comparado e seu registro de dados e hora. -
@@ -3,4 +3,5 @@mostra os números das linhas onde as alterações ocorrem. Neste caso, indica que as linhas 3 e 4 do arquivo original foram alteradas para as linhas 3 a 5 do arquivo modificado. -
user = input(Enter your name: )é uma linha do arquivo original. -
print(greet(user))é outra linha do arquivo original. -
+print("Nice to meet you")é uma linha adicional no arquivo modificado.
- Para ver a diferença em um formato lado a lado, você pode usar o
-ysinalizador:
diff -y hello.py also-hello.py
# Output
def greet(name): def greet(name):
return fHello, {name}! return fHello, {name}!
user = input(Enter your name: ) user = input(Enter your name: )
print(greet(user)) print(greet(user))
> print("Nice to meet you")
Na saída:
-
As linhas que são iguais em ambos os arquivos são exibidas lado a lado.
-
Linhas diferentes são mostradas com um
>símbolo caído que a linha está presente apenas em um dos arquivos.
Parte 5: Noções básicas de edição de texto no Linux
Habilidades de edição de texto usando uma linha de comando são uma das habilidades mais cruciais no Linux. Nesta seção, você aprenderá a usar dois editores de texto populares no Linux: Vim e Nano.
Sugiro que você domine qualquer editor de texto de sua escolha e se atenha a ele. Isso economizará seu tempo e o tornará mais produtivo. Vim e nano são escolhas seguras, pois estão presentes na maioria das distribuições Linux.
5.1. Dominando o Vim: O Guia Completo
Introdução ao Vim
O Vim é uma ferramenta popular de edição de texto para linha de comando. O Vim tem suas vantagens: é poderoso, personalizável e rápido. Aqui estão alguns motivos pelos quais você deve considerar aprender o Vim:
-
A maioria dos servidores é acessada via CLI, então, na administração de sistemas, você não precisa necessariamente de uma interface gráfica. Mas o Vim te dá suporte – ele sempre estará lá.
-
O Vim utiliza uma abordagem centrada no teclado, pois foi projetado para ser usado sem mouse, o que pode acelerar significativamente as tarefas de edição depois que você aprender os atalhos de teclado. Isso também o torna mais rápido do que ferramentas de interface gráfica.
-
Alguns utilitários do Linux, por exemplo, edição de tarefas cron, funcionam no mesmo formato de edição do Vim.
-
O Vim é adequado para todos – iniciantes e usuários avançados. Suporta buscas complexas por strings, buscas com destaque e muito mais. Por meio de plugins, o Vim oferece recursos estendidos para desenvolvedores e administradores de sistemas, incluindo autocompletar código, destaque de sintaxe, gerenciamento de arquivos, controle de versão e muito mais.
O Vim tem duas variações: Vim ( vim) e Vim tiny ( vi). O Vim tiny é uma versão menor do Vim que não possui alguns recursos do Vim.
Como começar a usar vim
Comece a usar o Vim com este comando:
vim your-file.txt
your-file.txt pode ser um arquivo novo ou um arquivo existente que você deseja editar.
Navegando no Vim: Dominando os modos de movimento e comando
Nos primeiros dias da CLI, os teclados não tinham teclas de seta. Portanto, a navegação era feita usando o conjunto de teclas disponíveis, hjkl sendo uma delas.
Por ser centrado no teclado, o uso de hjkl teclas pode acelerar muito as tarefas de edição de texto.
Observação: embora as teclas de seta funcionem perfeitamente, você ainda pode experimentar outras hjkl teclas para navegar. Algumas pessoas acham essa forma de navegação eficiente.
💡 Dica: Para lembrar a hjkl sequência, use isto: pendure -se para trás, pule para baixo, chute para cima, pule para frente.
Os três modos do Vim
Você precisa conhecer os três modos de operação do Vim e como alternar entre eles. As teclas se comportam de maneira diferente em cada modo de comando. Os três modos são os seguintes:
-
Modo de comando.
-
Modo de edição.
-
Modo visual.
Modo de Comando. Ao iniciar o Vim, você entra no modo de comando por padrão. Este modo permite acessar outros modos.
⚠ Para alternar para outros modos, você precisa estar presente no modo de comando primeiro
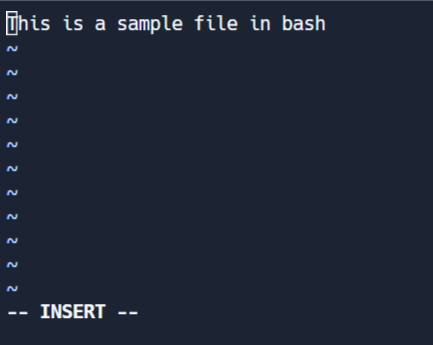
Modo de edição
Este modo permite que você faça alterações no arquivo. Para entrar no modo de edição, pressione I enquanto estiver no modo de comando. Observe a '-- INSERT' opção no final da tela.
Modo visual
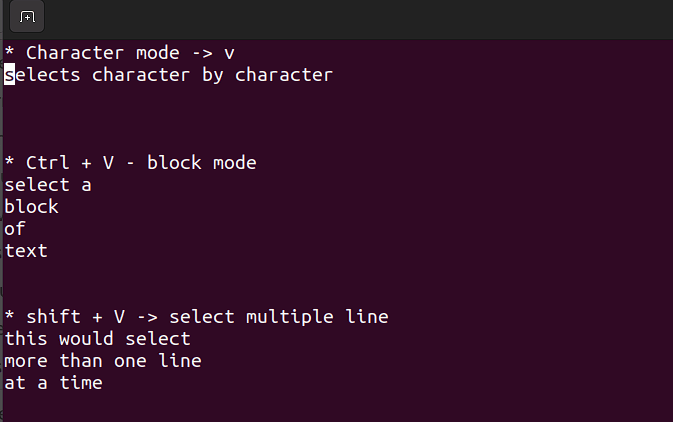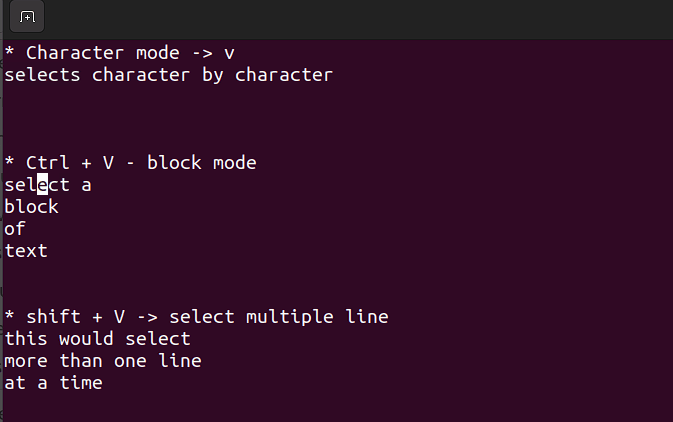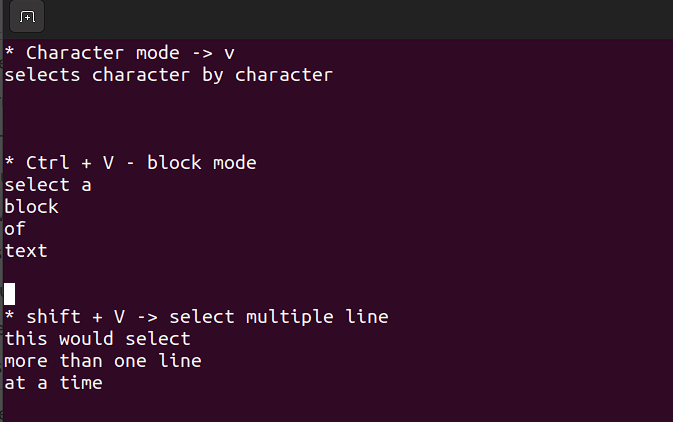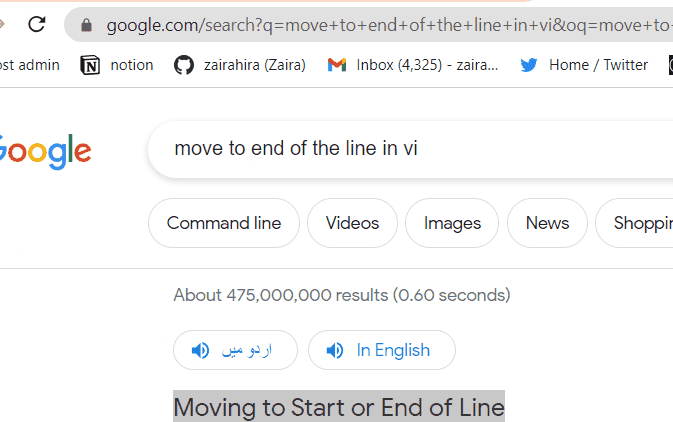
Este modo permite que você trabalhe com um único caractere, um bloco de texto ou linhas de texto. Vamos dividir em etapas simples. Lembre-se de usar as combinações abaixo no modo de comando.
-
Shift + V→ Selecione várias linhas. -
Ctrl + V→ Modo de bloqueio -
V→ Modo personagem
O modo visual é útil quando você precisa copiar e colar ou editar linhas em massa.
Modo de comando estendido.
O modo de comando estendido permite realizar operações avançadas, como pesquisar, definir números de linha e destacar texto. Abordaremos o modo estendido na próxima seção.
Como se manter no caminho certo? Se você esquecer o modo atual, basta pressionar ESC duas vezes e você retornará ao Modo de Comando.
Edição eficiente no Vim: copiar/colar e pesquisar
1. Como copiar e colar no Vim
Copiar e colar é conhecido como "yank" e "put" em termos Linux. Para copiar e colar, siga estes passos:
-
Selecione texto no modo visual.
-
Pressione
'y'para copiar/arrancar. -
Mova o cursor para a posição desejada e pressione
'p'.
2. Como pesquisar texto no Vim
Qualquer série de strings pode ser pesquisada com o Vim usando o / modo de comando. Para pesquisar, use /string-to-match.
No modo de comando, digite :set hls e pressione enter. Pesquise usando /string-to-match. Isso destacará as pesquisas.
Vamos pesquisar algumas strings:
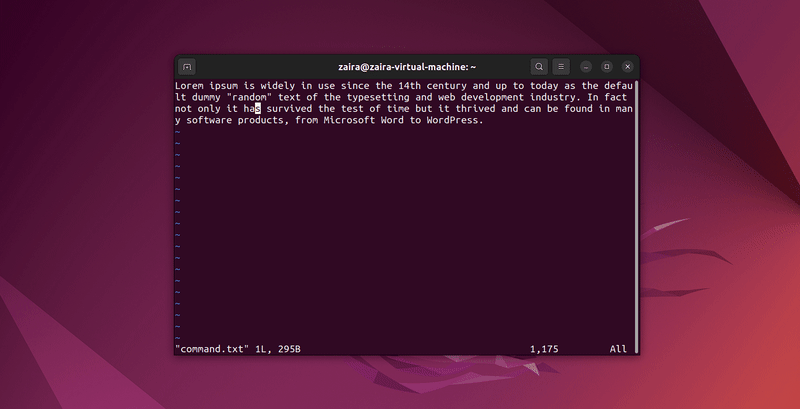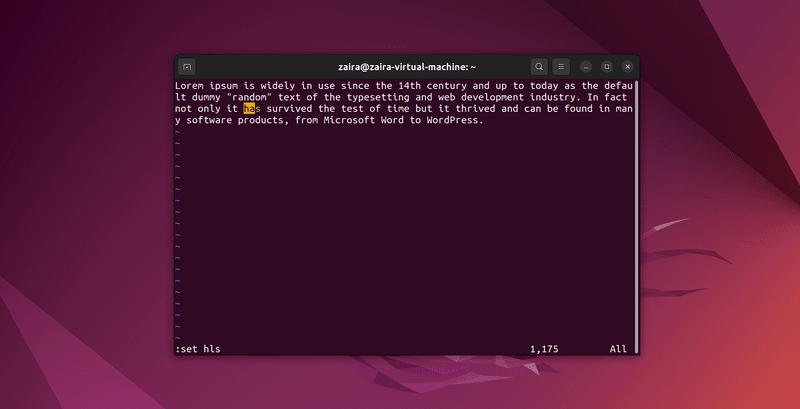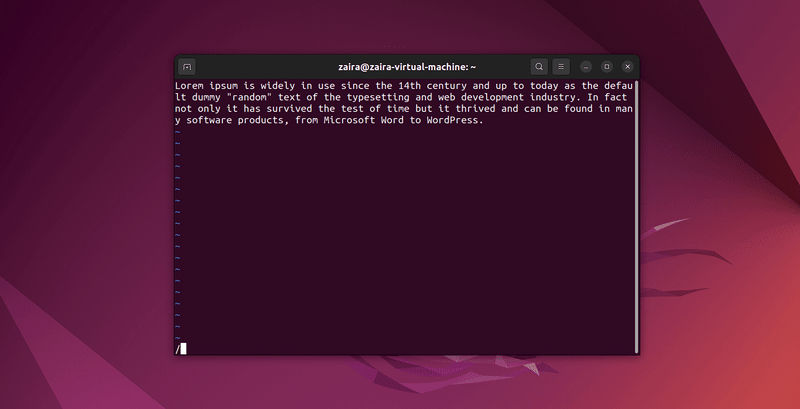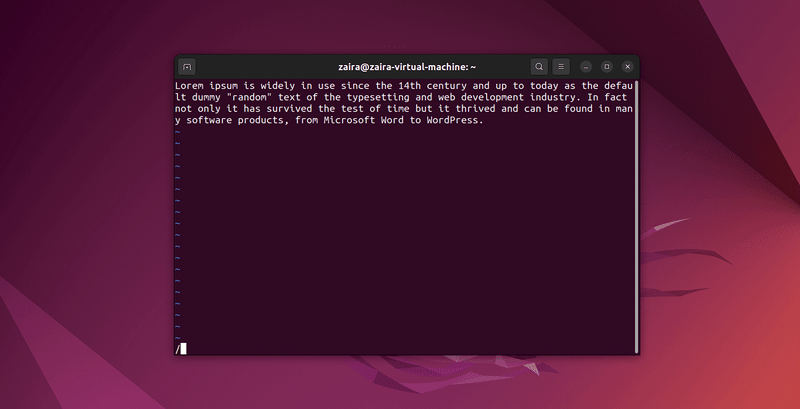
3. Como sair do Vim
Primeiro, vá para o modo de comando (pressionando escape duas vezes) e então use estes sinalizadores:
-
Sair sem salvar →
:q! -
Sair e salvar →
:wq!
Atalhos no Vim: tornando a edição mais rápida
Observação: todos esses atalhos funcionam somente no modo de comando.
-
Navegação básica
-
h: Mover para a esquerda -
j:Mover para baixo -
k: Mover para cima -
l: Mover para a direita -
0: Mover para o início da linha -
$: Mover para o final da linha -
gg: Mover para o início do arquivo -
G: Mover para o final do arquivo -
Ctrl+d: Mover meia página para baixo -
Ctrl+u: Mover meia página para cima
-
-
Edição
-
i:Entrar no modo de inserção antes do cursor -
I:Entrar no modo de inserção no início da linha -
a:Entrar no modo de inserção após o cursor -
A:Entrar no modo de inserção no final da linha -
o: Abra uma nova linha abaixo da linha atual e entre no modo de inserção -
O: Abra uma nova linha acima da linha atual e entre no modo de inserção -
x: Exclua o caractere sob o cursor -
dd: Excluir a linha atual -
yy: Yank (copiar) a linha atual (usar isto no modo visual) -
p: Colar abaixo do cursor -
P: Colar acima do cursor
-
-
Pesquisando e Substituindo
-
/: Procure um padrão que o levará à sua próxima ocorrência -
?: Procure um padrão que o levará à sua ocorrência anterior -
n: Repita a última pesquisa na mesma direção -
N: Repita a última pesquisa na direção oposta -
:%s/old/new/g: Substituir todas as ocorrências deoldwithnewno arquivo
-
-
Saindo
-
:w: Salve o arquivo, mas não saia -
:q: Sair do Vim (falha se houver alterações não salvas) -
:wqou:x: Salvar e sair -
:q!: Sair sem salvar
-
-
Várias janelas
-
:splitou:sp: Dividir a janela horizontalmente -
:vsplitou:vsp: Dividir a janela verticalmente -
Ctrl+w followed by h/j/k/l: Navegar entre janelas divididas
-
5.2. Dominando o Nano
Introdução ao Nano: o editor de texto fácil de usar
O Nano é um editor de texto intuitivo e fácil de usar, perfeito para iniciantes. Ele vem pré-instalado na maioria das distribuições Linux.
Para criar um novo arquivo usando o Nano, use o seguinte comando:
nano
Para começar a editar um arquivo existente com o Nano, use o seguinte comando:
nano filename
Lista de combinações de teclas no Nano
Vamos estudar as combinações de teclas mais importantes do Nano. Você as usará para realizar diversas operações, como salvar, sair, copiar, colar e muito mais.
Escreva em um arquivo e salve
Após abrir o Nano usando o nano comando, você pode começar a escrever o texto. Para salvar o arquivo, pressione Ctrl+O. Você será solicitado a inserir o nome do arquivo. Pressione Enter para salvar o arquivo.
Sair do nano
Você pode sair do Nano pressionando Ctrl+X. Se houver alterações não salvas, o Nano solicitará que você as salve antes de sair.
Copiando e colando
Para selecionar uma região, use ALT+A. Um marcador será exibido. Use as setas para selecionar o texto. Uma vez selecionado, saia do marcador com . ALT+^ .
Para copiar o texto selecionado, pressione Ctrl+K. Para colar o texto copiado, pressione Ctrl+U.
Cortar e colar
Selecione a região com ALT+A. Após a seleção, recorte o texto com Ctrl+K. Para colar o texto recortado, pressione Ctrl+U.
Navegação
Use Alt para ir para o início do arquivo.
Use Alt / para ir para o final do arquivo.
Visualizando números de linha
Ao abrir um arquivo com nano -l filename, você pode visualizar os números das linhas no lado esquerdo do arquivo.
Procurando
Você pode pesquisar um número de linha específico com ALt + G. Digite o número da linha no prompt e pressione Enter.
Você também pode iniciar a busca por uma string com CTRL + W e pressionar Enter. Se quiser pesquisar para trás, pressione Alt+W após iniciar a busca com Ctrl+W.
Resumo das combinações de teclas no Nano
-
Em geral
-
Ctrl+X: Sair do Nano (solicitando salvar se alterações forem feitas) -
Ctrl+O: Salve o arquivo -
Ctrl+R:Ler um arquivo no arquivo atual -
Ctrl+G: Exibir o texto de ajuda
-
-
Edição
-
Ctrl+K: Corta a linha atual e armazena-a no cutbuffer -
Ctrl+U: Cole o conteúdo do cutbuffer na linha atual -
Alt+6: Copie a linha atual e armazene-a no cutbuffer -
Ctrl+J: Justifique o parágrafo atual
-
-
Navegação
-
Ctrl+A: Mover para o início da linha -
Ctrl+E: Mover para o final da linha -
Ctrl+C: Exibe o número da linha atual e as informações do arquivo -
Ctrl+_(Ctrl+Shift+-): Ir para um número de linha (e opcionalmente, coluna) específico -
Ctrl+Y: Role uma página para cima -
Ctrl+V: Role uma página para baixo
-
-
Pesquisar e substituir
-
Ctrl+W: Pesquisar uma string (e depoisEnterpesquisar novamente) -
Alt+W: Repita a última pesquisa, mas na direção oposta -
Ctrl+: Pesquisar e substituir
-
-
Variado
-
Ctrl+T: Invocar o corretor ortográfico, se disponível -
Ctrl+D: Apaga o caractere sob o cursor (não o corta) -
Ctrl+L: Atualizar (redesenhar) a tela atual -
Alt+U: Desfazer a última operação -
Alt+E: Refazer a última operação desfeita
-
Parte 6: Script Bash
6.1. Definição de script Bash
Um script bash é um arquivo que contém uma sequência de comandos executados pelo programa bash linha por linha. Ele permite que você execute uma série de ações, como navegar para um diretório específico, criar uma pasta e iniciar um processo usando a linha de comando.
Ao salvar comandos em um script, você pode repetir a mesma sequência de etapas várias vezes e executá-las executando o script.
6.2. Vantagens do Bash Scripting
O script Bash é uma ferramenta poderosa e versátil para automatizar tarefas de administração do sistema, gerenciar recursos do sistema e executar outras tarefas de rotina em sistemas Unix/Linux.
Algumas vantagens do shell script são:
-
Automação : scripts de shell permitem automatizar tarefas e processos repetitivos, economizando tempo e reduzindo o risco de erros que podem ocorrer com a execução manual.
-
Portabilidade : scripts de shell podem ser executados em várias plataformas e sistemas operacionais, incluindo Unix, Linux, macOS e até mesmo Windows, por meio do uso de emuladores ou máquinas virtuais.
-
Flexibilidade : Os scripts de shell são altamente personalizáveis e podem ser facilmente modificados para atender a requisitos específicos. Eles também podem ser combinados com outras linguagens de programação ou utilitários para criar scripts mais poderosos.
-
Acessibilidade : Scripts de shell são fáceis de escrever e não requerem nenhuma ferramenta ou software especial. Eles podem ser editados usando qualquer editor de texto, e a maioria dos sistemas operacionais possui um interpretador de shell integrado.
-
Integração : scripts de shell podem ser integrados com outras ferramentas e aplicativos, como bancos de dados, servidores web e serviços de nuvem, permitindo tarefas mais complexas de automação e gerenciamento de sistemas.
-
Depuração : scripts de shell são fáceis de depurar, e a maioria dos shells tem ferramentas integradas de depuração e relatório de erros que podem ajudar a identificar e corrigir problemas rapidamente.
6.3. Visão geral do Bash Shell e da Interface de Linha de Comando
Os termos "shell" e "bash" são frequentemente usados indistintamente. Mas há uma diferença sutil entre os dois.
O termo "shell" refere-se a um programa que fornece uma interface de linha de comando para interagir com um sistema operacional. Bash (Bourne-Again SHell) é um dos shells Unix/Linux mais usados e é o shell padrão em muitas distribuições Linux.
Até agora, os comandos que você estava digitando eram basicamente inseridos em um "shell".
Embora o Bash seja um tipo de shell, existem outros shells disponíveis, como o Korn shell (ksh), o C shell (csh) e o Z shell (zsh). Cada shell tem sua própria sintaxe e conjunto de recursos, mas todos compartilham o propósito comum de fornecer uma interface de linha de comando para interagir com o sistema operacional.
Você pode determinar seu tipo de shell usando o ps comando:
ps
# output:
PID TTY TIME CMD
20506 pts/0 00:00:00 bash <--- the shell type
20931 pts/0 00:00:00 ps
Em resumo, enquanto "shell" é um termo amplo que se refere a qualquer programa que fornece uma interface de linha de comando, "Bash" é um tipo específico de shell amplamente utilizado em sistemas Unix/Linux.
Observação: nesta seção, usaremos o shell "bash".
6.4. Como criar e executar scripts Bash
Convenções de nomenclatura de script
Por convenção de nomenclatura, scripts bash terminam com .sh. No entanto, scripts bash podem ser executados perfeitamente sem a sh extensão.
Adicionando o Shebang
Os scripts Bash começam com shebang. Shebang é uma combinação de bash # e bang ! seguido pelo caminho do shell bash. Esta é a primeira linha do script. Shebang instrui o shell a executá-lo via shell bash. Shebang é simplesmente um caminho absoluto para o interpretador bash.
Abaixo está um exemplo da declaração shebang.
#!/bin/bash
Você pode encontrar o caminho do seu shell bash (que pode ser diferente do acima) usando o comando:
which bash
Criando seu primeiro script bash
Nosso primeiro script solicita que o usuário insira um caminho. Em resposta, seu conteúdo será listado.
Crie um arquivo chamado run_all.sh usando qualquer editor de sua escolha.
vim run_all.sh
Adicione os seguintes comandos ao seu arquivo e salve-o:
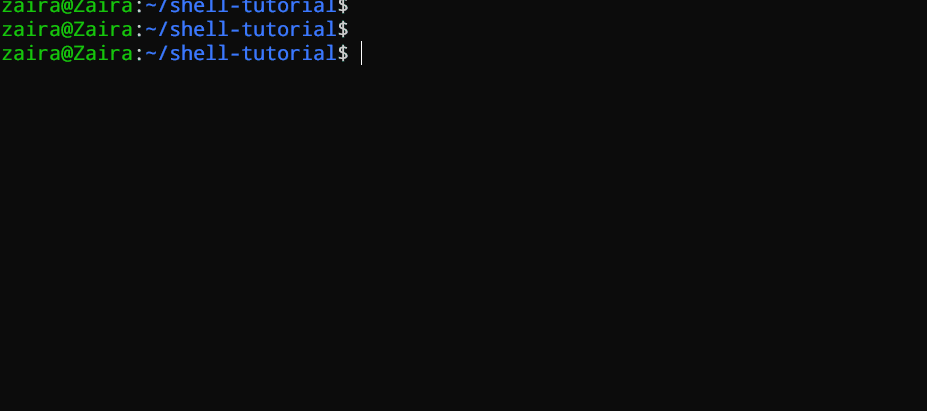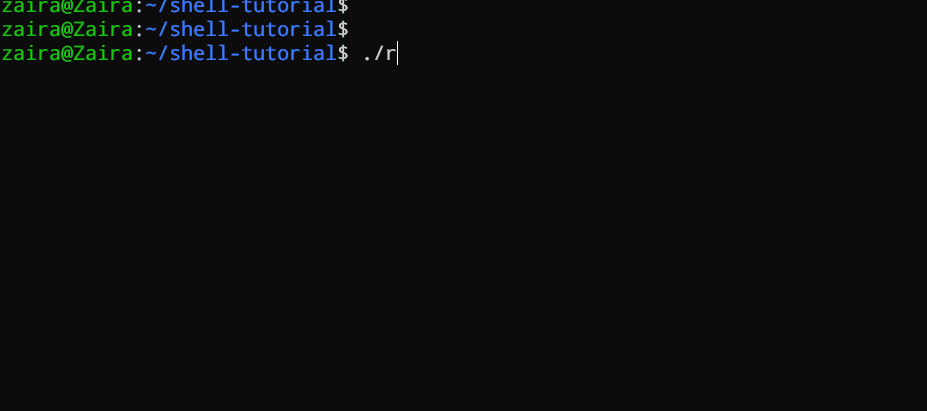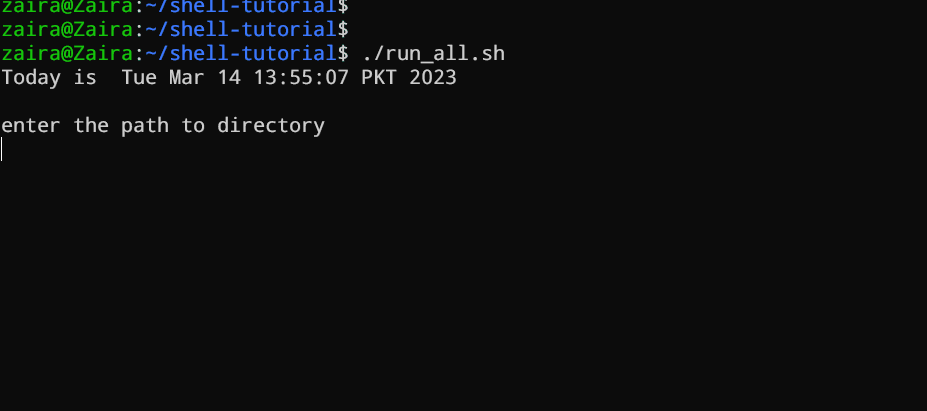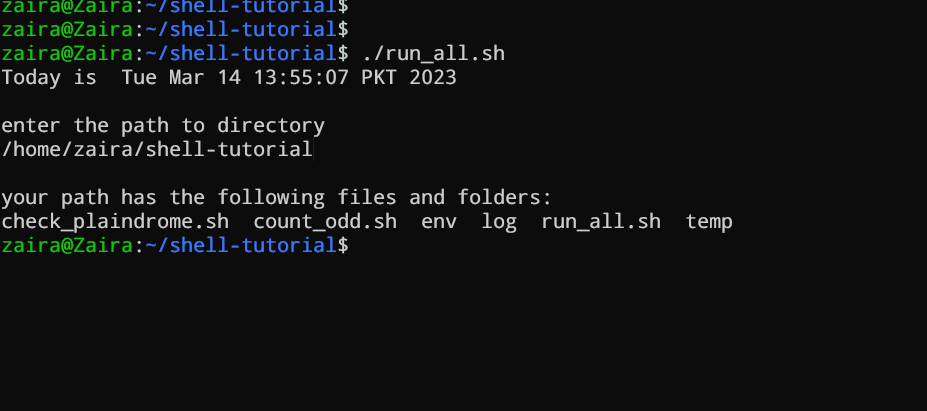
#!/bin/bash
echo "Today is " `date`
echo -e "
enter the path to directory"
read the_path
echo -e "
you path has the following files and folders: "
ls $the_path
Vamos analisar o script linha por linha com mais detalhes. Estou exibindo o mesmo script novamente, mas desta vez com números de linha.
1 #!/bin/bash
2 echo "Today is " `date`
3
4 echo -e "
enter the path to directory"
5 read the_path
6
7 echo -e "
you path has the following files and folders: "
8 ls $the_path
-
Linha 1: O shebang (
#!/bin/bash) aponta para o caminho do shell bash. -
Linha 2: O
echocomando exibe a data e a hora atuais no terminal. Observe que "dateestá entre acentos graves". -
Linha 4: Queremos que o usuário insira um caminho válido.
-
Linha 5: O
readcomando lê a entrada e a armazena na variávelthe_path. -
linha 8: O
lscomando pega a variável com o caminho armazenado e exibe os arquivos e pastas atuais.
Executando o script bash
Para tornar o script seguinte, atribua direitos de execução ao seu usuário usando este comando:
chmod u+x run_all.sh
Aqui,
-
chmodmodifica a propriedade de um arquivo para o usuário atual:u. -
+xAdicionados os direitos de execução ao usuário atual. Isso significa que o usuário proprietário agora pode executar o script. -
run_all.shé o arquivo que desejamos executar.
Você pode executar o script usando qualquer um dos métodos recomendados:
-
sh run_all.sh -
bash run_all.sh -
./run_all.sh
Vamos vê-lo funcionando em ação 🚀
6.5. Noções básicas de script Bash
Comentários no script bash
Os comentários começam com um #no script bash. Isso significa que qualquer linha que comece com um # é um comentário e será ignorada pelo intérprete.
Os comentários são muito úteis para documentar o código, e é uma boa prática adicioná-los para ajudar outros a entender o código.
Estes são exemplos de comentários:
# This is an example comment
# Both of these lines will be ignored by the interpreter
Variáveis e tipos de dados em Bash
Variáveis permitem armazenar dados. Você pode usá-los para ler, acessar e manipular dados em todo o seu script.
Não há tipos de dados no Bash. No Bash, uma variável é capaz de armazenar valores numéricos, caracteres individuais ou sequências de caracteres.
No Bash, você pode usar e definir os valores das variáveis das seguintes maneiras:
- Atribuir ou valor diretamente:
country=Netherlands
2. Atribuir o valor com base na saída obtida de um programa ou comando, usando substituições de comandos. Observe que isso $é necessário para acessar o valor de uma variável existente.
same_country=$country
Isso atribui o valor countryà nova variável same_country.
Para acessar o valor da variável, anexe $ao nome da variável.
country=Netherlands
echo $country
# output
Netherlands
new_country=$country
echo $new_country
# output
Netherlands
Acima, você pode ver um exemplo de atribuição e impressão de valores de variáveis.
Convenções de nomenclatura de variáveis
No script Bash, as seguintes são as convenções de nomenclatura de variáveis:
-
Os nomes das variáveis devem começar com uma letra ou um sublinhado (
_). -
Os nomes de variáveis podem conter letras, números e sublinhados (
_). -
Os nomes de variáveis foram diferenciadas de subsidiárias.
-
Os nomes de variáveis não devem conter espaços ou caracteres especiais.
-
Use nomes descritivos que reflitam especificamente da variável.
-
Evite usar palavras-chave reservadas, como
if,then,else,fi, e assim por diante, como nomes de variáveis.
Aqui estão alguns exemplos de nomes de variáveis válidos no Bash:
name
count
_var
myVar
MY_VAR
Aqui estão alguns exemplos de nomes de variáveis inválidos:
# invalid variable names
2ndvar (variable name starts with a number)
my var (variable name contains a space)
my-var (variable name contains a hyphen)
Seguir essas convenções de nomenclatura ajuda a tornar os scripts Bash mais legíveis e simples de manter.
Entrada e saída em scripts Bash
Coletando informações
Nesta seção, discutiremos alguns métodos para fornecer entrada aos nossos scripts.
- Lendo a entrada do usuário e armazenando-a em uma variável
Podemos ler a entrada do usuário usando o readcomando.
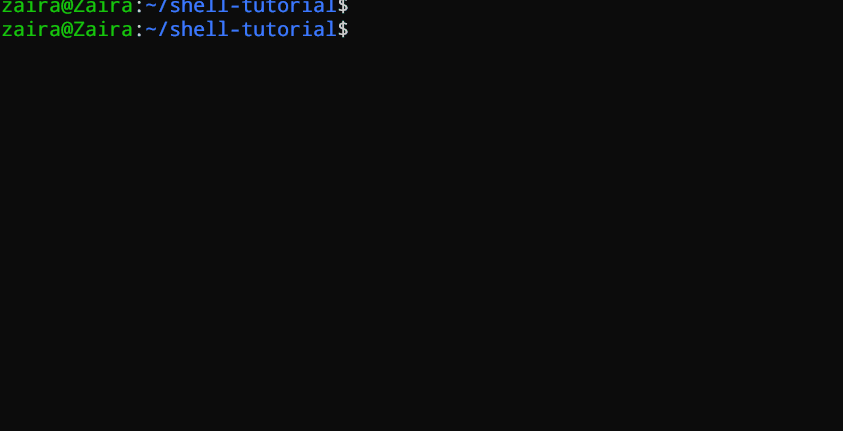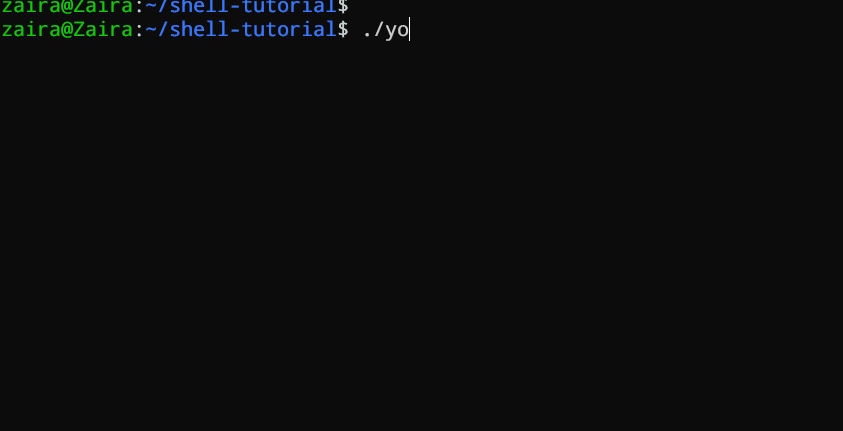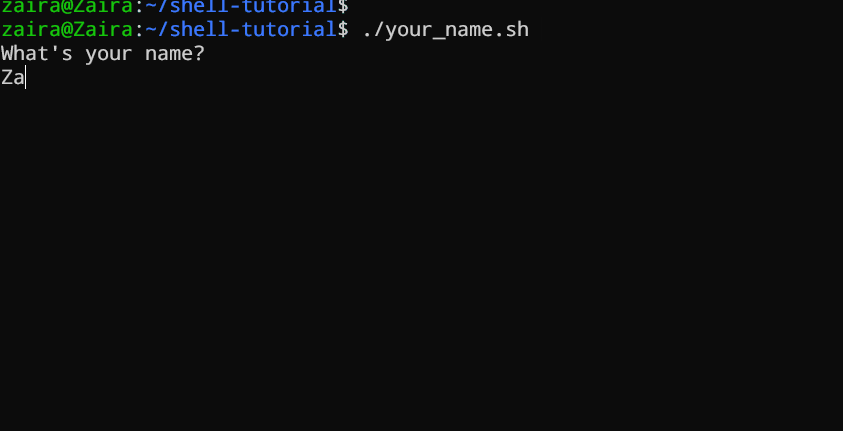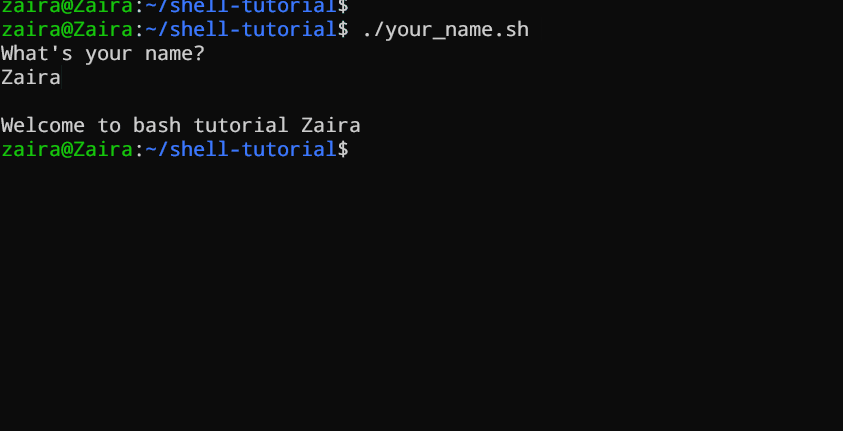
#!/bin/bash
echo "What's your name?"
read entered_name
echo -e "
Welcome to bash tutorial" $entered_name
2. Lendo um arquivo
Este código lê cada linha de um arquivo chamado input.txte imprime no terminal. Estudaremos os laços enquanto mais adiante nesta seção.
while read line
do
echo $line
done < input.txt
3. Argumentos da linha de comando
Em um script ou função bash, $1denota o argumento inicial passado, $2denota o segundo argumento passado e assim por diante.
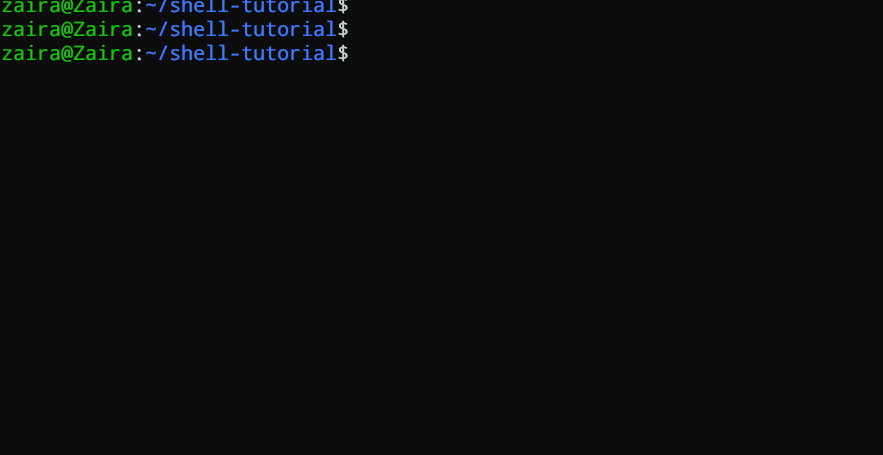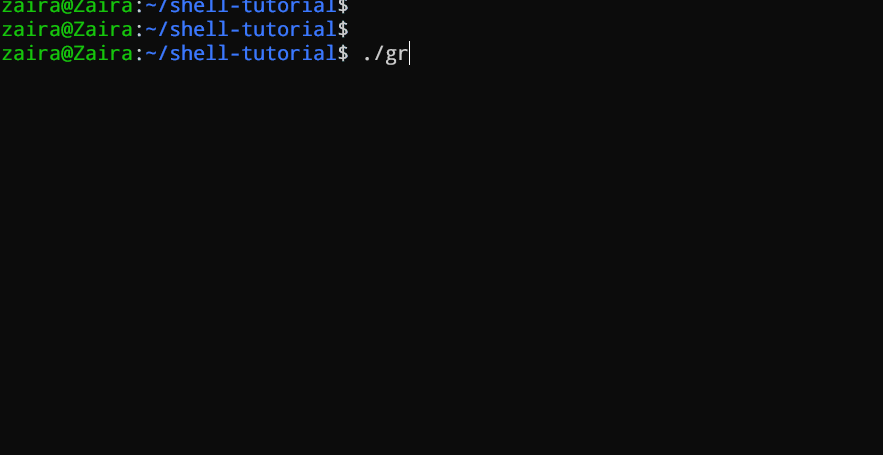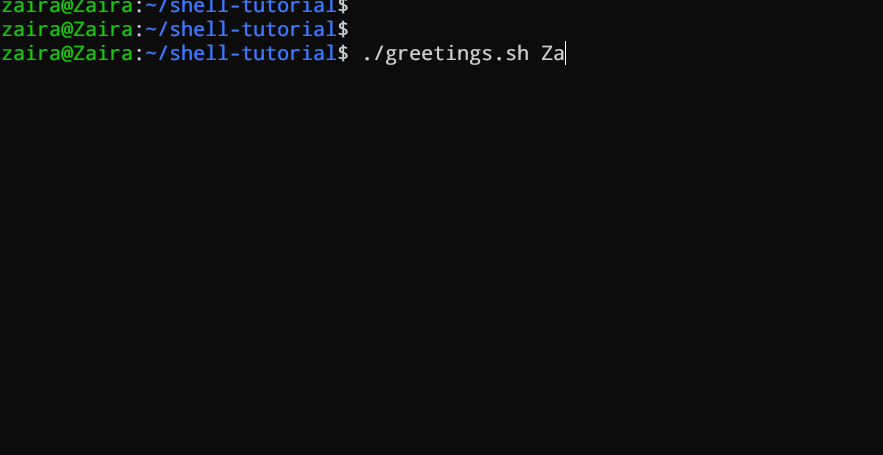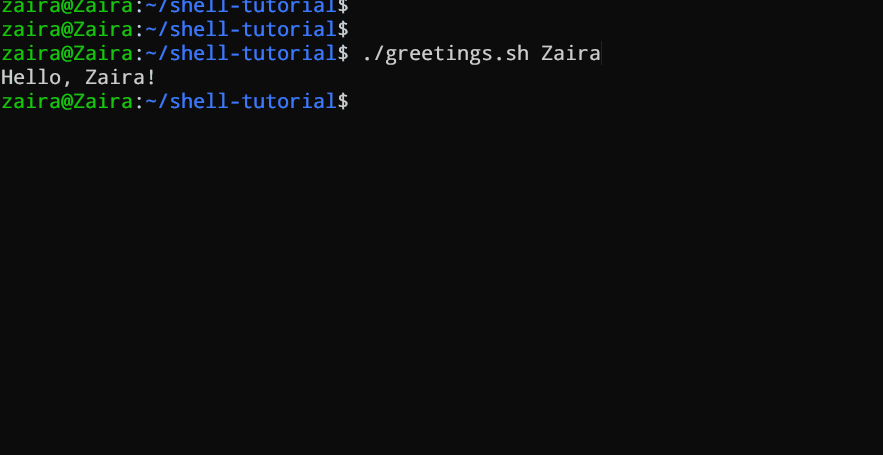
Este script recebe um nome como argumento de linha de comando e imprime uma saudação personalizada.
#!/bin/bash
echo "Hello, $1!"
Nós fornecemos Zairacomo argumento o roteiro.
Saída:
Exibindo saída
Aqui discutiremos alguns métodos para obter a saída dos scripts.
- Impressão no terminal:
echo "Hello, World!"
Isso imprime o texto "Olá, Mundo!" nenhum terminal.
2. Escrevendo em um arquivo:
echo "This is some text." > output.txt
Isso grave o texto "Este é um texto." em um arquivo chamado output.txt. Observe que o >operador sobrescreve um arquivo se ele já tiver algum conteúdo.
3. Anexando a um arquivo:
echo "More text." >> output.txt
Isso acrescenta o texto "Mais texto" ao final do arquivo output.txt.
4. Redirecionando a saída:
ls > files.txt
Isso lista os arquivos no diretório atual e grava a saída em um arquivo chamado files.txt. Você pode redirecionar a saída de qualquer comando para um arquivo desse formato.
Você aprenderá sobre o redirecionamento de saída em detalhes na seção 8.5.
Declarações condicionais (if/else)
Expressões que produzem um resultado booleano, verdadeiro ou falso, são chamadas de condições. Existem várias maneiras de avaliar condições, incluindo if, if-else, if-elif-elsee condicionais aninhadas.
Sintaxe :
if [[ condition ]];
then
statement
elif [[ condition ]]; then
statement
else
do this by default
fi
Sintaxe das instruções condicionais do bash
Podemos usar operadores lógicos como AND -ae OR -opara fazer comparações que tenham mais significado.
if [ $a -gt 60 -a $b -lt 100 ]
Esta instrução verifica se ambas as condições são true: aé maior que 60E bé menor que 100.
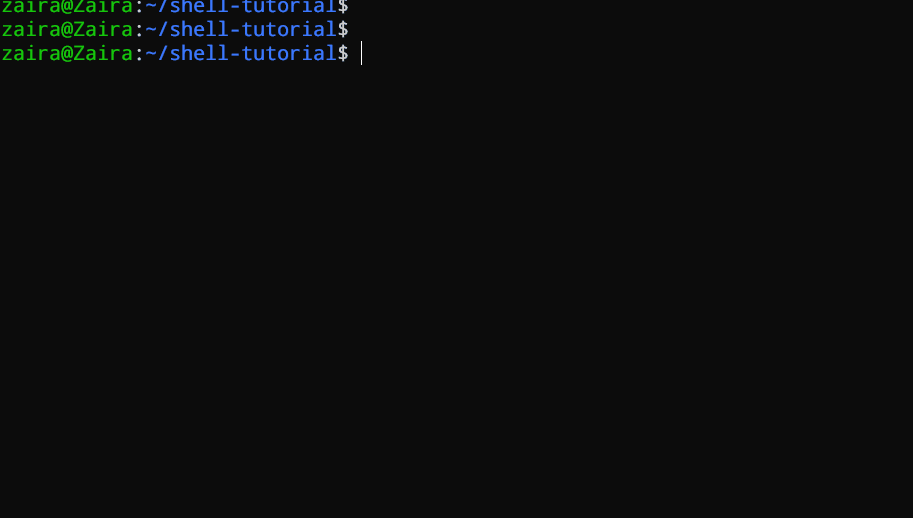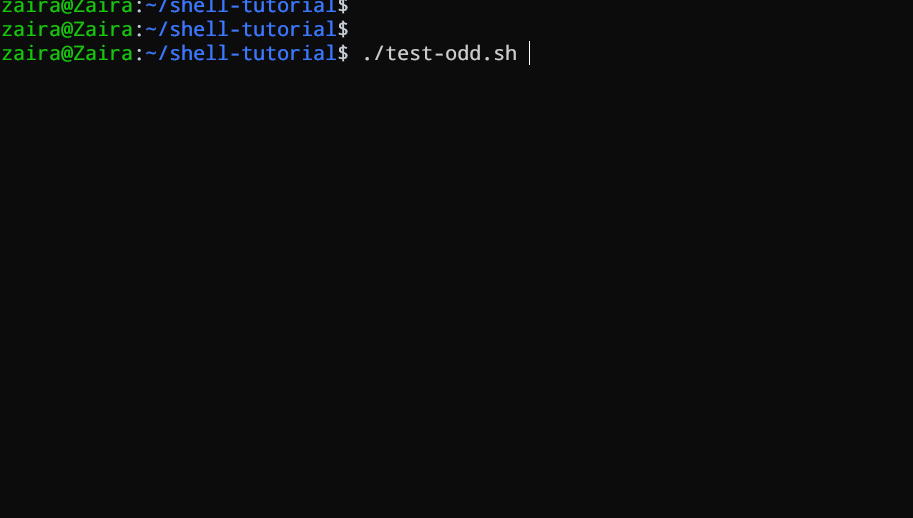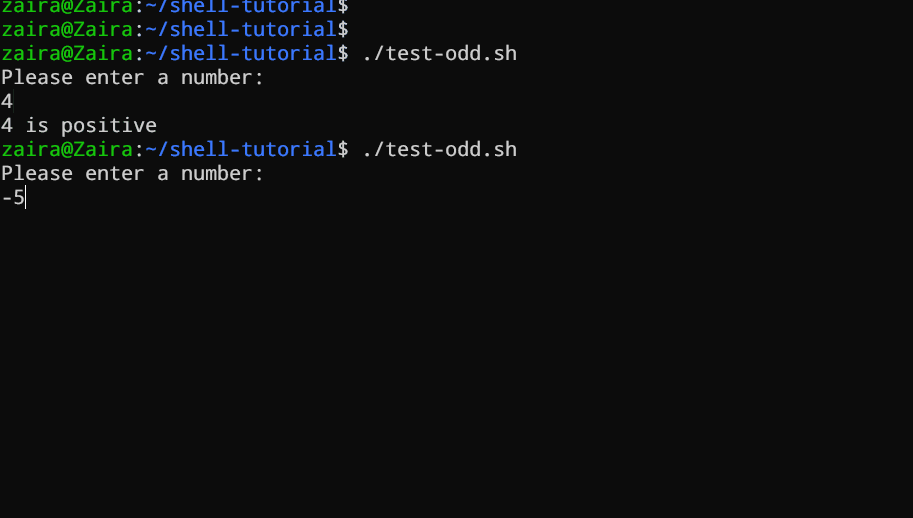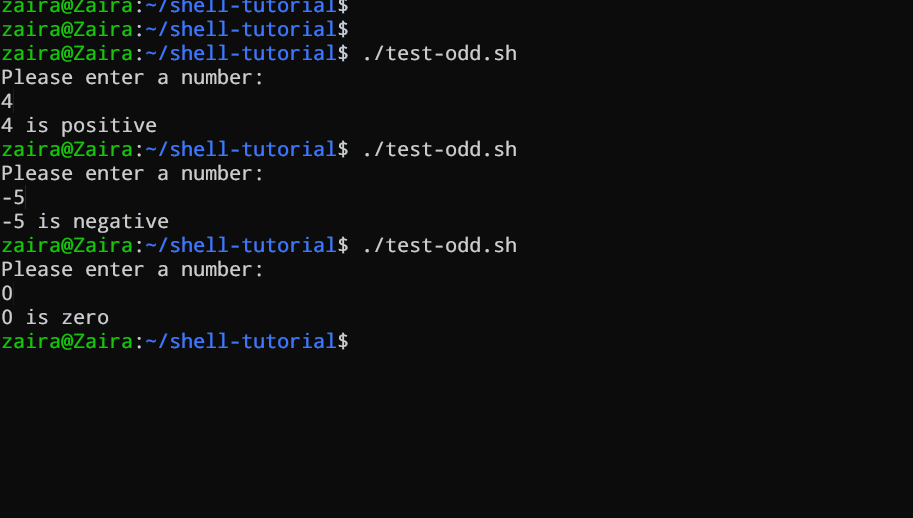
Vejamos um exemplo de um script Bash que usa instruções e ifpara determinar se um número inserido pelo usuário é positivo, negativo ou zero:if-elseif-elif-else
#!/bin/bash
# Script to determine if a number is positive, negative, or zero
echo "Please enter a number: "
read num
if [ $num -gt 0 ]; then
echo "$num is positive"
elif [ $num -lt 0 ]; then
echo "$num is negative"
else
echo "$num is zero"
fi
O script primeiro solicita que o usuário insira um número. Em seguida, ele usa uma ifinstrução para verificar se o número é maior que 0. Em caso afirmativo, o script informa que o número é positivo. Se o número não for maior que 0, o script passa para a próxima instrução, que é uma if-elif instrução.
Aqui, o script verifica se o número é menor que 0 . Se for, o script retorna que o número é negativo.
Por fim, se o número não for maior 0nem menor que 0, o script usa uma else instrução para informar que o número é zero.
Vendo em ação 🚀
Looping e ramificação em Bash
Enquanto o laço
Os loops "while" verificam a existência de uma condição e executam o loop até que ela permaneça true. Precisamos fornecer uma instrução de contador que incremente o contador para controlar a execução do loop.
No exemplo abaixo, (( i += 1 ))está a instrução counter que incrementa o valor de i. O loop será executado exatamente 10 vezes.
#!/bin/bash
i=1
while [[ $i -le 10 ]] ; do
echo "$i"
(( i += 1 ))
done

Para laço
O forloop, assim como o whileloop, permite que você execute instruções um número específico de vezes. Cada loop difere em sua sintaxe e uso.
No exemplo abaixo, o loop irá iterar 5 vezes.
#!/bin/bash
for i in {1..5}
do
echo $i
done

Declarações de caso
No Bash, as instruções case são usadas para comparar um valor específico com uma lista de padrões e executar um bloco de código com base no primeiro padrão correspondente. A sintaxe de uma instrução case no Bash é a seguinte:
case expression in
pattern1)
# code to execute if expression matches pattern1
;;
pattern2)
# code to execute if expression matches pattern2
;;
pattern3)
# code to execute if expression matches pattern3
;;
*)
# code to execute if none of the above patterns match expression
;;
esac
Aqui, "expressão" é o valor que queremos comparar, e "padrão1", "padrão2", "padrão3" e assim por diante são os padrões com os quais queremos comparar.
O ponto e vírgula duplo ";;" separa cada bloco de código a ser executado para cada padrão. O asterisco "*" representa o caso padrão, que é executado se nenhum dos padrões especificados corresponder à expressão.
Vejamos um exemplo:
fruit="apple"
case $fruit in
"apple")
echo "This is a red fruit."
;;
"banana")
echo "This is a yellow fruit."
;;
"orange")
echo "This is an orange fruit."
;;
*)
echo "Unknown fruit."
;;
esac
Neste exemplo, como o valor de fruit é apple, o primeiro padrão corresponde e o bloco de código que ecoa This is a red fruit. é executado. Se o valor de fruit fosse banana, o segundo padrão corresponderia e o bloco de código que ecoa This is a yellow fruit. seria executado, e assim por diante.
Se o valor de fruit não corresponder a nenhum dos padrões especificados, o caso padrão será executado, o que ecoa Unknown fruit.
Parte 7: Gerenciando Pacotes de Software no Linux
O Linux vem com vários programas integrados. Mas talvez seja necessário instalar novos programas de acordo com suas necessidades. Também pode ser necessário atualizar os aplicativos existentes.
7.1. Pacotes e Gerenciamento de Pacotes
O que é um pacote?
Um pacote é uma coleção de arquivos agrupados. Esses arquivos são essenciais para a execução de um programa específico. Eles contêm os arquivos executáveis, bibliotecas e outros recursos do programa.
Além dos arquivos necessários para a execução do programa, os pacotes também contêm scripts de instalação, que copiam os arquivos para onde são necessários. Um programa pode conter muitos arquivos e dependências. Com pacotes, é mais fácil gerenciar todos os arquivos e dependências de uma só vez.
Qual é a diferença entre fonte e binário?
Os programadores escrevem o código-fonte em uma linguagem de programação. Esse código-fonte é então compilado em código de máquina que o computador pode entender. O código compilado é chamado de código binário.
Ao baixar um pacote, você pode obter o código-fonte ou o código binário. O código-fonte é o código legível por humanos que pode ser compilado em código binário. O código binário é o código compilado que o computador consegue entender.
Pacotes de código-fonte podem ser usados com qualquer tipo de máquina, desde que o código-fonte seja compilado corretamente. Binários, por outro lado, são códigos compilados específicos para um tipo específico de máquina ou arquitetura.
Você pode encontrar a arquitetura da sua máquina usando o uname -m comando.
uname -m
# output
x86_64
Dependências de pacotes
Os programas frequentemente compartilham arquivos. Em vez de incluir esses arquivos em cada pacote, um pacote separado pode disponibilizá-los para todos os programas.
Para instalar um programa que precise desses arquivos, você também deve instalar o pacote que os contém. Isso é chamado de dependência de pacote. Especificar dependências torna os pacotes menores e mais simples, reduzindo duplicatas.
Ao instalar um programa, suas dependências também devem ser instaladas. A maioria das dependências necessárias geralmente já está instalada, mas algumas extras podem ser necessárias. Portanto, não se surpreenda se vários outros pacotes forem instalados junto com o pacote escolhido. Essas são as dependências necessárias.
Gerenciadores de pacotes
O Linux oferece um sistema abrangente de gerenciamento de pacotes para instalar, atualizar, configurar e remover software.
Com o gerenciamento de pacotes, você pode ter acesso a uma base organizada de milhares de pacotes de software, além de poder resolver dependências e verificar atualizações de software.
Os pacotes podem ser gerenciados usando utilitários de linha de comando que podem ser facilmente automatizados por administradores de sistema ou por meio de uma interface gráfica.
Canais/repositórios de software
⚠️ O gerenciamento de pacotes varia de acordo com a distribuição. Aqui, estamos usando o Ubuntu.
A instalação de software é um pouco diferente no Linux em comparação ao Windows e Mac.
O Linux usa repositórios para armazenar pacotes de software. Um repositório é uma coleção de pacotes de software disponíveis para instalação por meio de um gerenciador de pacotes.
Um gerenciador de pacotes também armazena um índice de todos os pacotes disponíveis em um repositório. Às vezes, o índice é reconstruído para garantir que esteja atualizado e para saber quais pacotes foram atualizados ou adicionados ao canal desde a última verificação.
O processo genérico de download de software de um repositório se parece com isto:
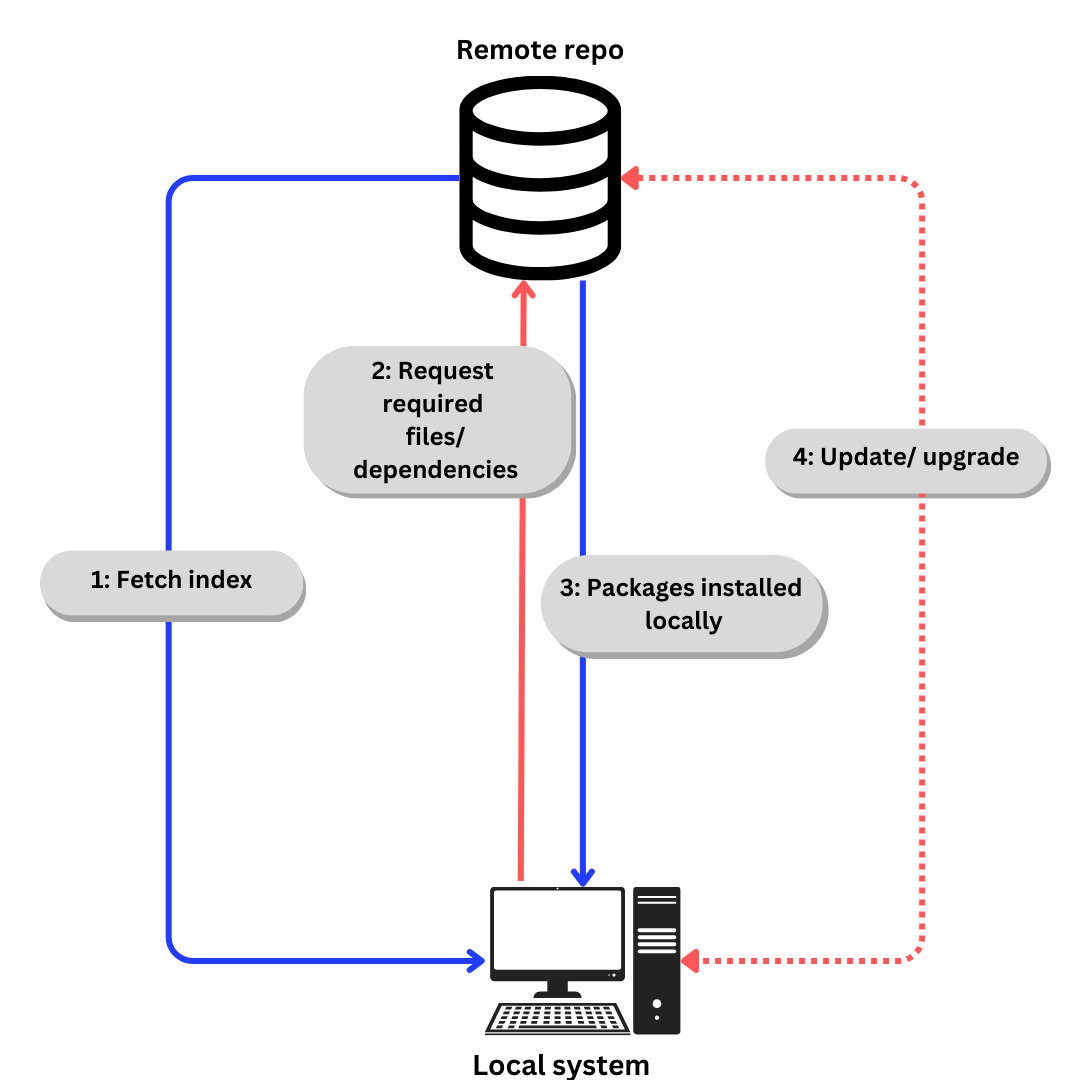
Se falarmos especificamente do Ubuntu,
-
O índice é obtido usando
apt update.(apté explicado na próxima seção). -
Arquivos/dependências necessários solicitados de acordo com o índice usando
apt install -
Pacotes e dependências instalados localmente.
-
Atualize dependências e pacotes quando necessário usando
apt updateeapt upgrade
Em distribuições baseadas em Debian, você pode arquivar a lista de repositórios em /etc/apt/sources.list.
7.2. Instalando um pacote via linha de comando
O apt comando é uma poderosa ferramenta de linha de comando, que funciona com a "Advanced Packaging Tool (APT)" do Ubuntu.
apt, juntamente com os comandos incluídos, fornece os meios para instalar novos pacotes de software, atualizar pacotes de software existentes, atualizar o índice da lista de pacotes e até mesmo atualizar todo o sistema Ubuntu.
Para visualizar os logs da instalação usando apt, você pode visualizar o /var/log/dpkg.log arquivo.
A seguir estão os usos do aptcomando:
Instalando pacotes
Por exemplo, para instalar o htoppacote, você pode usar o seguinte comando:
sudo apt install htop
Atualizando o índice da lista de pacotes
O índice da lista de pacotes contém todos os pacotes disponíveis nos repositórios. Para atualizar o índice da lista de pacotes locais, você pode usar o seguinte comando:
sudo apt update
Atualizando os pacotes
Os pacotes instalados em seu sistema podem receber atualizações de correções de bugs, patches de segurança e novos recursos.
Para atualizar os pacotes, você pode usar o seguinte comando:
sudo apt upgrade
Removendo pacotes
Para remover um pacote, como htop, você pode usar o seguinte comando:
sudo apt remove htop
7.3. Instalando um pacote por meio de um método gráfico avançado – Synaptic
Se não se sentir confortável com a linha de comando, você pode usar uma GUI do aplicativo para instalar pacotes. Você pode obter os mesmos resultados da linha de comando, mas com uma interface gráfica.
O Synaptic é um aplicativo de gerenciamento de pacotes com interface gráfica que ajuda a listar os pacotes instalados, seu status, atualizações pendentes e assim por diante. Ele oferece filtros personalizados para ajudar a refinar os resultados da pesquisa.
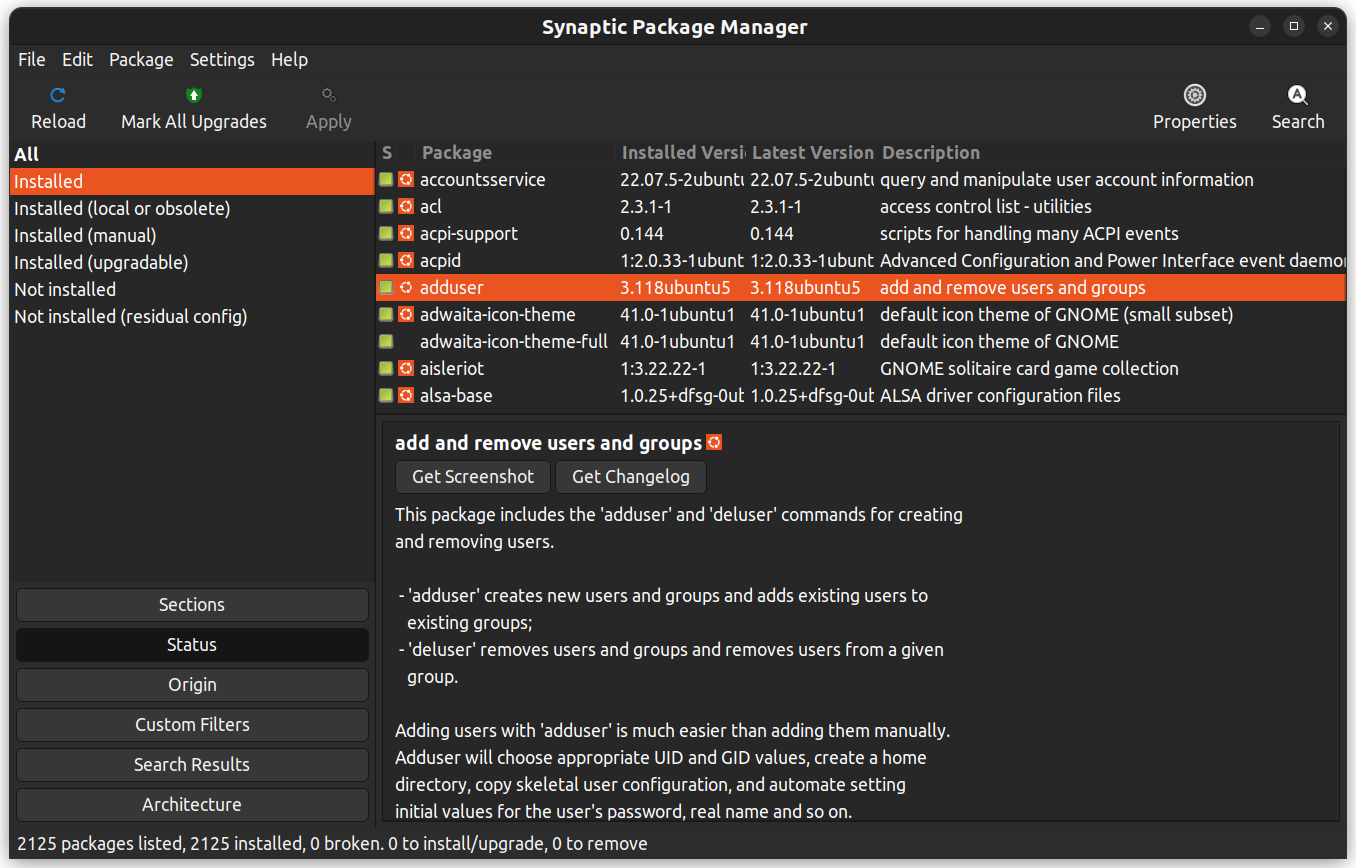
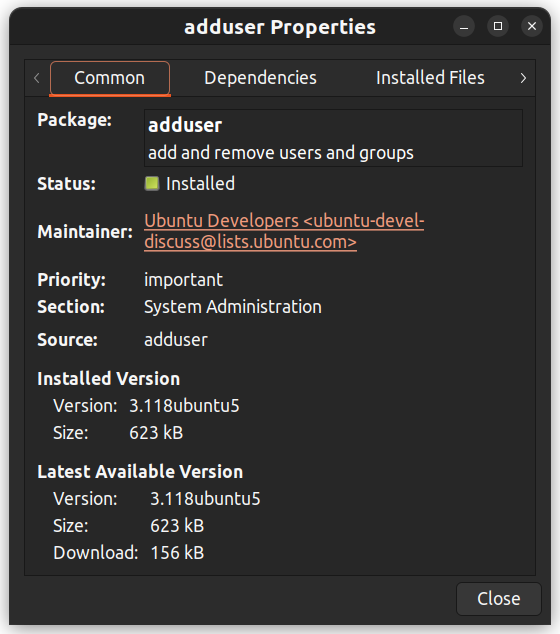
Você também pode clicar com o botão direito do mouse em um pacote e visualizar mais detalhes, como dependências, manutenção, tamanho e arquivos instalados.
7.4. Instalando pacotes baixados de um site
Talvez você queira instalar um pacote baixado de um site, em vez de um repositório de software. Esses pacotes são chamados de .debarquivos.
Usando dpkgpara instalar pacotes:dpkg é uma ferramenta de linha de comando usada para instalar pacotes. Para instalar um pacote com dpkg , abra o Terminal e digite o seguinte:
cd directory
sudo dpkg -i package_name.deb
Nota: Substitua "diretório" pelo diretório onde o pacote está armazenado e "nome_do_pacote" pelo nome do arquivo do pacote.
Como alternativa, você pode clicar com o botão direito, selecionar "Abrir com outro aplicativo" e escolher um aplicativo GUI de sua escolha.
💡 Dica: No Ubuntu, você pode ver uma lista de pacotes instalados com dpkg --list.
Parte 8: Tópicos avançados sobre Linux
8.1. Gerenciamento de usuários
Vários usuários podem ter diferentes níveis de acesso em um sistema. No Linux, o usuário root tem o nível de acesso mais alto e pode executar qualquer operação no sistema. Os usuários comuns têm acesso limitado e só podem executar operações para as quais tenham permissão.
O que é um usuário?
Uma conta de usuário fornece separação entre diferentes pessoas e programas que podem executar comandos.
Os humanos identificam os usuários por um nome, já que os nomes são simples de trabalhar. Mas o sistema identifica os usuários por um número exclusivo chamado ID do usuário (UID).
Quando usuários humanos efetuam login usando o nome de usuário fornecido, eles precisam usar uma senha para se autorizar.
As contas de usuário específicas são baseadas na segurança do sistema. A propriedade dos arquivos também está associada às contas de usuário e exige o controle de acesso aos arquivos. Cada processo tem uma conta de usuário associado que fornece uma camada de controle para os administradores.
Existem três tipos principais de contas de usuário:
-
Superusuário : O superusuário tem acesso completo ao sistema. O nome do superusuário é
root. Ele tem um valorUIDde 0. -
Usuário do sistema : O usuário do sistema possui contas de usuário usadas para executar serviços do sistema. Essas contas são usadas para executar serviços do sistema e não se destinam à interação humana.
-
Usuário regular : Usuários regulares são usuários humanos que têm acesso ao sistema.
O idcomando exibe o ID do usuário e o ID do grupo do usuário atual.
id
uid=1000(john) gid=1000(john) groups=1000(john),4(adm),24(cdrom),27(sudo),30(dip)... output truncated
Para visualizar as informações básicas de outro usuário, passe o nome de usuário como argumento para o id comando.
id username
Para visualizar informações relacionadas ao usuário para processos, use o ps comando com o -u sinalizador.
ps -u
# Output
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
root 1 0.0 0.1 16968 3920 ? Ss 18:45 0:00 /sbin/init splash
root 2 0.0 0.0 0 0 ? S 18:45 0:00 [kthreadd]
Por padrão, os sistemas usam o /etc/passwd arquivo para armazenar informações do usuário.
Aqui está uma linha do /etc/passwd arquivo:
root:x:0:0:root:/root:/bin/bash
O /etc/passwd arquivo contém as seguintes informações sobre cada usuário:
-
Nome de usuário:
root– O nome de usuário da conta de usuário. -
Senha:
x– A senha em formato criptografado para a conta de usuário que é armazenada no/etc/shadowarquivo por motivos de segurança. -
ID do usuário (UID):
0– O identificador numérico exclusivo da conta do usuário. -
ID do grupo (GID):
0– O identificador de grupo principal para a conta de usuário. -
Informações do usuário:
root– O nome real da conta do usuário. -
Diretório inicial:
/root– O diretório inicial da conta do usuário. -
Shell:
/bin/bash– O shell padrão para a conta de usuário. Um usuário do sistema pode usá-lo/sbin/nologincaso logins interativos não sejam permitidos para ele.
O que é um grupo?
Um grupo é um conjunto de contas de usuários que compartilham acesso e recursos. Os grupos têm nomes de grupo para identificá-los. O sistema identifica os grupos por um número exclusivo chamado ID do grupo (GID).
Por padrão, as informações sobre grupos são armazenadas no /etc/group arquivo.
Aqui está uma entrada do /etc/group arquivo:
adm:x:4:syslog,john
Aqui está o detalhamento dos campos na entrada fornecida:
-
Nome do grupo:
adm– O nome do grupo. -
Senha:
x– A senha do grupo é armazenada no/etc/gshadowarquivo por motivos de segurança. A senha é opcional e aparece em branco se não for definida. -
ID do grupo (GID):
4– O identificador numérico exclusivo do grupo. -
Membros do grupo:
syslog,john– A lista de nomes de usuários que são membros do grupo. Neste caso, o grupoadmtem dois membros:syslogejohn.
Nesta entrada específica, o nome do grupo é adm, o ID do grupo é 4, e o grupo tem dois membros: syslog e john. O campo de senha normalmente é definido como x para indicar que a senha do grupo está armazenada no /etc/gshadow arquivo.
Os grupos são divididos em grupos " primários" e " suplementares" .
-
Grupo Primário: Por padrão, cada usuário recebe um grupo primário. Esse grupo geralmente tem o mesmo nome do usuário e é criado quando a conta é criada. Arquivos e diretórios criados pelo usuário normalmente pertencem a esse grupo primário.
-
Grupos Suplementares: São grupos extras aos quais um usuário pode pertencer, além do seu grupo principal. Os usuários podem ser membros de vários grupos suplementares. Esses grupos permitem que o usuário tenha permissões para recursos compartilhados entre eles. Eles ajudam a fornecer acesso a recursos compartilhados sem afetar as permissões de arquivo do sistema e mantendo a segurança intacta. Embora um usuário deva pertencer a um grupo principal, pertencer a grupos suplementares é opcional.
Controle de acesso: encontrando e entendendo a permissão de arquivo
A propriedade do arquivo pode ser visualizada usando o ls -l comando. A primeira coluna na saída do ls -l comando mostra as permissões do arquivo. As outras colunas mostram o proprietário do arquivo e o grupo ao qual o arquivo pertence.

Vamos dar uma olhada mais de perto na mode coluna:
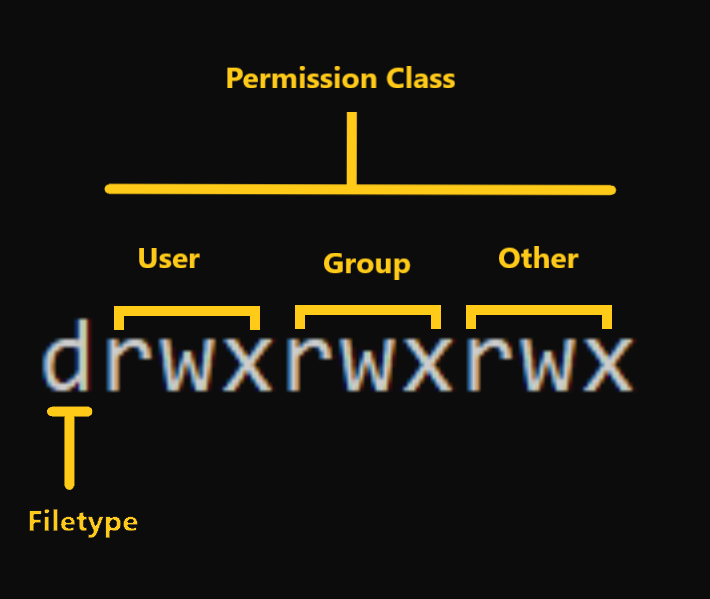
O modo define duas coisas:
-
Tipo de arquivo: O tipo de arquivo define o tipo do arquivo. Para arquivos comuns que contêm dados simples, o símbolo é
-. Para outros tipos de arquivo especiais, o símbolo é diferente. Para um diretório que é um arquivo especial, o símbolo éd. Arquivos especiais são tratados de forma diferente pelo sistema operacional. -
Classes de permissão: O próximo conjunto de caracteres define as permissões para usuário, grupo e outros, respectivamente.
– Usuário : Este é o proprietário de um arquivo e o proprietário do arquivo pertence a esta classe.
– Grupo : Os membros do grupo do arquivo pertencem a esta classe
– Outros : Todos os usuários que não fazem parte das classes de usuário ou grupo pertencem a esta classe.
💡 Dica: A propriedade do diretório pode ser visualizada usando o ls -ld comando.
Como ler permissões simbólicas ou as rwx permissões
A rwx representação é conhecida como Representação Simbólica de Permissões. No conjunto de permissões,
-
rsignifica leitura . É indicado no primeiro caractere da tríade. -
wsignifica escrever . É indicado no segundo caractere da tríade. -
xsignifica execução . É indicado no terceiro caractere da tríade.
Ler:
Para arquivos comuns, as permissões de leitura permitem que o arquivo seja aberto e somente leitura. Os usuários não podem modificar o arquivo.
Da mesma forma para diretórios, as permissões de leitura permitem a listagem do conteúdo do diretório sem qualquer modificação no diretório.
Escrever:
Quando os arquivos têm permissões de gravação, o usuário pode modificar (editar, excluir) o arquivo e salvá-lo.
Para pastas, as permissões de gravação permitem que um usuário modifique seu conteúdo (crie, exclua e renomeie os arquivos dentro delas) e modifique o conteúdo dos arquivos para os quais o usuário tem permissões de gravação.
Exemplos de permissões no Linux
Agora que sabemos como ler permissões, vamos ver alguns exemplos.
-
-rwx------: Um arquivo que só é acessível e executável por seu proprietário.-rw-rw-r--: Um arquivo que está aberto à modificação por seu proprietário e grupo, mas não por outros. -
drwxrwx---: Um diretório que pode ser modificado por seu proprietário e grupo.
Executar:
Para arquivos, as permissões de execução permitem que o usuário execute um script executável. Para diretórios, o usuário pode acessá-los e obter detalhes sobre os arquivos contidos neles.
Como alterar permissões e propriedade de arquivos no Linux usando chmod e chown
Agora que sabemos os conceitos básicos de propriedades e permissões, vamos ver como podemos modificar permissões usando o chmod comando.
Sintaxe dechmod :
chmod permissions filename
Onde,
-
permissionspode ser lido, escrito, executado ou uma combinação deles. -
filenameé o nome do arquivo cujas permissões precisam ser alteradas. Este parâmetro também pode ser uma lista de arquivos cujas permissões devem ser alteradas em massa.
Podemos alterar permissões usando dois modos:
-
Modo simbólico : este método usa símbolos como
u,g,opara representar usuários, grupos e outros. As permissões são representadas comor, w, xleitura, gravação e execução, respectivamente. Você pode modificar as permissões usando +, - e =. -
Modo absoluto : este método representa permissões como números octais de 3 dígitos variando de 0 a 7.
Agora, vamos vê-los em detalhes.
Como alterar permissões usando o modo simbólico
A tabela abaixo resume a representação do usuário:
| REPRESENTAÇÃO DO USUÁRIO | DESCRIÇÃO |
| você | usuário/proprietário |
| g | grupo |
| o | outro |
Podemos usar operadores matemáticos para adicionar, remover e atribuir permissões. A tabela abaixo mostra o resumo:
| OPERADOR | DESCRIÇÃO |
| + | Adiciona uma permissão a um arquivo ou diretório |
| – | Remove a permissão |
| = | Define a permissão se ela não estiver presente anteriormente. Também substitui as permissões definidas anteriormente. |
Exemplo:
Suponha que eu tenha um script e queira torná-lo executável para o proprietário do arquivo zaira.
As permissões de arquivo atuais são as seguintes:

Vamos dividir as permissões assim:
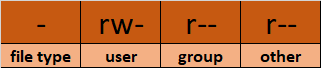
Para adicionar direitos de execução ( x) ao proprietário ( u) usando o modo simbólico, podemos usar o comando abaixo:
chmod u+x mymotd.sh
Saída:
Agora, podemos ver que as permissões de execução foram adicionadas para o proprietário zaira.
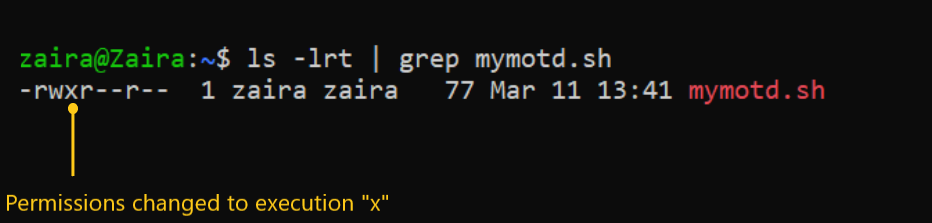
Exemplos adicionais para alterar permissões via método simbólico:
-
Removendo
readewritepermissão paragroupeothers:chmod go-rw. -
Removendo
readpermissões paraothers:chmod o-r. -
Atribuindo
writepermissãogroupe substituindo permissão existente:chmod g=w.
Como alterar permissões usando o modo absoluto
O modo absoluto usa números para representar permissões e operadores matemáticos para modificá-las.
A tabela abaixo mostra como podemos atribuir permissões relevantes:
| PERMISSÃO | FORNECER PERMISSÃO |
| ler | adicione 4 |
| escrever | adicione 2 |
| executar | adicione 1 |
As permissões podem ser revogadas por subtração. A tabela abaixo mostra como você pode remover permissões relevantes.
| PERMISSÃO | REVOGAR PERMISSÃO |
| ler | subtrair 4 |
| escrever | subtrair 2 |
| executar | subtrair 1 |
Exemplo :
- Defina
read(adicione 4) parauser,read(adicione 4) eexecute(adicione 1) para o grupo e somenteexecute(adicione 1) para os outros.
chmod 451 file-name
Foi assim que realizamos o cálculo:
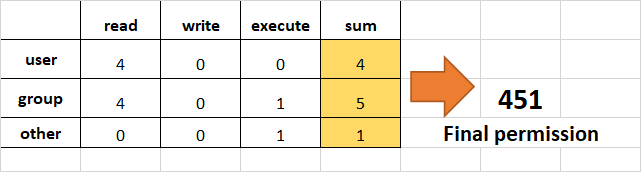
Note que isto é o mesmo que r--r-x--x.
- Remover
executiondireitos deotheregroup.
Para remover a execução de other e group, subtraia 1 da parte de execução dos últimos 2 octetos.
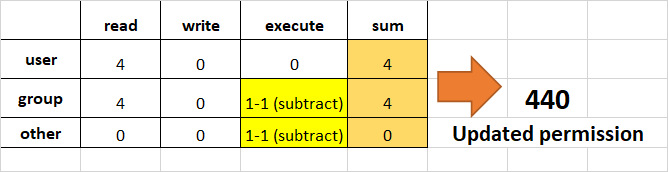
- Atribuir
read,writeeexecuteparauser,readeexecuteparagroupe somentereadpara outros.
Isso seria o mesmo que rwxr-xr--.
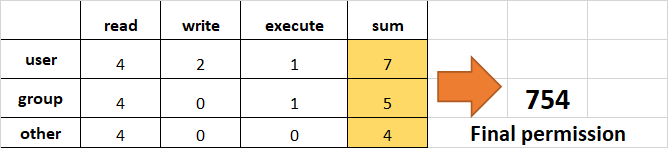
Como alterar a propriedade usando o chown comando
A seguir, aprenderemos como alterar a propriedade de um arquivo. Você pode alterar a propriedade de um arquivo ou pasta usando o chown comando . Em alguns casos, a alteração da propriedade requer sudo permissões.
Sintaxe de chown:
chown user filename
Como alterar a propriedade do usuário com chown
Vamos transferir a propriedade de usuário zaira para usuário news.
chown news mymotd.sh
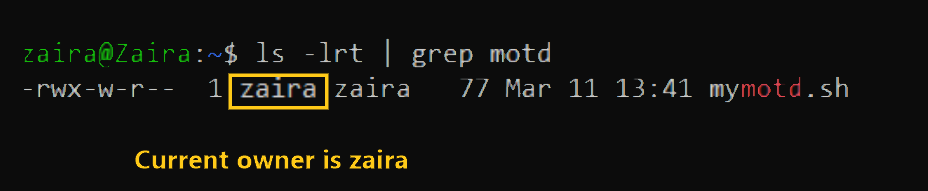
Comando para alterar a propriedade: sudo chown news mymotd.sh.
Saída:

Como alterar a propriedade do usuário e do grupo simultaneamente
Também podemos usar chown para alterar usuário e grupo simultaneamente.
chown user:group filename
Como alterar a propriedade do diretório
Você pode alterar a propriedade recursivamente para o conteúdo de um diretório. O exemplo abaixo altera a propriedade da /opt/script pasta para permitir o usuário admin.
chown -R admin /opt/script
Como alterar a propriedade do grupo
Caso precisemos apenas alterar o proprietário do grupo, podemos usar chown o prefixo "dono do grupo" antes do nome do grupo. :
chown :admins /opt/script
Como alternar entre usuários
Você pode alternar entre usuários usando o su comando.
[user01@host ~]$ su user02
Password:
[user02@host ~]$
Como obter acesso de superusuário
O superusuário, ou usuário root, tem o nível mais alto de acesso em um sistema Linux. O usuário root pode executar qualquer operação no sistema. Ele pode acessar todos os arquivos e diretórios, instalar e remover softwares e modificar ou substituir configurações do sistema.
Com grandes poderes vêm grandes responsabilidades. Se o usuário root for comprometido, alguém pode obter controle total sobre o sistema. É aconselhável usar a conta de usuário root apenas quando necessário.
Se você omitir o nome de usuário, o su comando alternará para a conta de usuário root por padrão.
[user01@host ~]$ su
Password:
[root@host ~]#
Outra variação do su comando é su -. O su comando alterna para a conta de usuário root, mas não altera as variáveis de ambiente. O su - comando alterna para a conta de usuário root e altera as variáveis de ambiente para as do usuário alvo.
Executando comandos com sudo
Para executar comandos como root usuário sem alternar para a root conta de usuário, você pode usar o sudo comando . O sudo comando permite executar comandos com privilégios elevados.
Executar comandos com sudo é uma opção mais segura do que executá-los como root usuário. Isso ocorre porque apenas um conjunto específico de usuários pode receber permissão para executar comandos com sudo. Isso é definido no /etc/sudoers arquivo.
Além disso, sudo registra todos os comandos executados com ele, fornecendo um registro de auditoria de quem executou quais comandos e quando.
No Ubuntu, você pode encontrar os logs de auditoria aqui:
cat /var/log/auth.log | grep sudo
Para um usuário que não tem acesso a sudo, ele é sinalizado em logs e exibe uma mensagem como esta:
user01 is not in the sudoers file. This incident will be reported.
Gerenciando contas de usuários locais
Criando usuários a partir da linha de comando
O comando usado para adicionar um novo usuário é:
sudo useradd username
Este comando configura o diretório inicial de um usuário e cria um grupo privado designado pelo nome de usuário. Atualmente, a conta não possui uma senha válida, o que impede o usuário de efetuar login até que uma senha seja criada.
Modificando usuários existentes
O usermod comando é usado para modificar usuários existentes. Aqui estão algumas das opções comuns usadas com o usermod comando:
Aqui estão alguns exemplos do usermod comando no Linux:
-
Alterar o nome de login de um usuário:
sudo usermod -l newusername oldusername -
Alterar o diretório inicial de um usuário:
sudo usermod -d /new/home/directory -m username -
Adicionar um usuário a um grupo suplementar:
sudo usermod -aG groupname username -
Alterar o shell de um usuário:
sudo usermod -s /bin/bash username -
Bloquear conta de usuário:
sudo usermod -L username -
Desbloquear a conta de um usuário:
sudo usermod -U username -
Defina uma data de expiração para uma conta de usuário:
sudo usermod -e YYYY-MM-DD username -
Alterar o ID de usuário (UID) de um usuário:
sudo usermod -u newUID username -
Alterar o grupo principal de um usuário:
sudo usermod -g newgroup username -
Remover um usuário de um grupo suplementar:
sudo gpasswd -d username groupname
Excluindo usuários
O userdel comando é usado para excluir uma conta de usuário e arquivos relacionados do sistema.
-
sudo userdel username: remove os detalhes do usuário/etc/passwd, mas mantém o diretório inicial do usuário. -
O
sudo userdel -r usernamecomando remove os detalhes do usuário/etc/passwde também exclui o diretório inicial do usuário.
Alterando senhas de usuários
O passwd comando é usado para alterar a senha de um usuário.
sudo passwd username: define a senha inicial ou altera a senha existente do nome de usuário. Também é usado para alterar a senha do usuário conectado no momento.
8.2 Conexão com servidores remotos via SSH
Acessar servidores remotos é uma das tarefas essenciais para administradores de sistemas. Você pode se conectar a diferentes servidores ou acessar bancos de dados através da sua máquina local e executar comandos, tudo usando SSH.
O que é o protocolo SSH?
SSH significa Secure Shell. É um protocolo de rede criptográfico que permite a comunicação segura entre dois sistemas.
A porta padrão para SSH é 22.
Os dois participantes enquanto se comunicam via SSH são:
-
O servidor: a máquina à qual você deseja acessar.
-
O cliente: O sistema a partir do qual você está acessando o servidor.
A conexão a um servidor segue estas etapas:
-
Iniciar conexão: o cliente envia uma solicitação de conexão ao servidor.
-
Troca de Chaves: O servidor envia sua chave pública ao cliente. Ambos concordam com os métodos de criptografia a serem utilizados.
-
Geração de chave de sessão: o cliente e o servidor usam a troca de chaves Diffie-Hellman para criar uma chave de sessão compartilhada.
-
Autenticação do cliente: o cliente efetua login no servidor usando uma senha, chave privada ou outro método.
-
Comunicação segura: após a autenticação, o cliente e o servidor se comunicam com segurança com criptografia.
Como se conectar a um servidor remoto usando SSH?
O ssh comando é um utilitário integrado ao Linux e também o padrão. Ele torna o acesso aos servidores bastante fácil e seguro.
Aqui, estamos falando sobre como o cliente faria uma conexão com o servidor.
Antes de se conectar a um servidor, você precisa ter as seguintes informações:
-
O endereço IP ou o nome de domínio do servidor.
-
O nome de usuário e a senha do servidor.
-
O número da porta à qual você tem acesso no servidor.
A sintaxe básica do ssh comando é:
ssh username@server_ip
Por exemplo, se seu nome de usuário for john e o IP do servidor for 192.168.1.10, o comando seria:
ssh john@192.168.1.10
Depois disso, você será solicitado a digitar a senha secreta. Sua tela será semelhante a esta:
john@192.168.1.10's password:
Welcome to Ubuntu 20.04.2 LTS (GNU/Linux 5.4.0-70-generic x86_64)
* Documentation: https://help.ubuntu.com
* Management: https://landscape.canonical.com
* Support: https://ubuntu.com/advantage
System information as of Fri Jun 5 10:17:32 UTC 2024
System load: 0.08 Processes: 122
Usage of /: 12.3% of 19.56GB Users logged in: 1
Memory usage: 53% IP address for eth0: 192.168.1.10
Swap usage: 0%
Last login: Fri Jun 5 09:34:56 2024 from 192.168.1.2
john@hostname:~$ # start entering commands
Agora você pode executar os comandos relevantes no servidor 192.168.1.10.
⚠️ A porta padrão para SSH é 22 , mas também é vulnerável, pois hackers provavelmente tentarão acessá-la primeiro. Seu servidor pode expor outra porta e compartilhar o acesso com você. Para se conectar a uma porta diferente, use o -p sinalizador .
ssh -p port_number username@server_ip
8.3. Análise e Análise de Logs Avançadas
Arquivos de log, quando configurados, são gerados pelo seu sistema por diversos motivos úteis. Eles podem ser usados para rastrear eventos do sistema, monitorar o desempenho do sistema e solucionar problemas. São especialmente úteis para administradores de sistema, que podem rastrear erros de aplicativos, eventos de rede e atividades do usuário.
Aqui está um exemplo de um arquivo de log:
# sample log file
2024-04-25 09:00:00 INFO Startup: Application starting
2024-04-25 09:01:00 INFO Config: Configuration loaded successfully
2024-04-25 09:02:00 DEBUG Database: Database connection established
2024-04-25 09:03:00 INFO User: New user registered (UserID: 1001)
2024-04-25 09:04:00 WARN Security: Attempted login with incorrect credentials (UserID: 1001)
2024-04-25 09:05:00 ERROR Network: Network timeout on request (ReqID: 456)
2024-04-25 09:06:00 INFO Email: Notification email sent (UserID: 1001)
2024-04-25 09:07:00 DEBUG API: API call with response time over threshold (Duration: 350ms)
2024-04-25 09:08:00 INFO Session: User session ended (UserID: 1001)
2024-04-25 09:09:00 INFO Shutdown: Application shutdown initiated
Um arquivo de log geralmente contém as seguintes colunas:
-
Carimbo de data/hora: data e hora em que o evento ocorreu.
-
Nível de log: a gravidade do evento (INFO, DEBUG, WARN, ERROR).
-
Componente: O componente do sistema que gerou o evento (Inicialização, Configuração, Banco de dados, Usuário, Segurança, Rede, E-mail, API, Sessão, Desligamento).
-
Mensagem: Uma descrição do evento que ocorreu.
-
Informações adicionais: Informações adicionais relacionadas ao evento.
Em sistemas de tempo real, os arquivos de log tendem a ter milhares de linhas e são gerados a cada segundo. Eles podem ser muito extensos, dependendo da configuração. Cada coluna em um arquivo de log é uma informação que pode ser usada para rastrear problemas. Isso torna os arquivos de log difíceis de ler e entender manualmente.
É aqui que entra a análise sintática de logs. A análise sintática de logs é o processo de extrair informações úteis de arquivos de log. Envolve dividir os arquivos de log em partes menores e mais fáceis de gerenciar, e extrair as informações relevantes.
As informações filtradas também podem ser úteis para criar alertas, relatórios e painéis.
Nesta seção, você explorará algumas técnicas para analisar arquivos de log no Linux.
Extração de texto usando grep
Grep é um utilitário integrado ao bash. Significa "impressão de expressão regular global". Grep é usado para corresponder strings em arquivos.
Aqui estão alguns usos comuns de grep:
-
Pesquisar uma sequência específica em um arquivo:
grep "search_string" filenameEste comando procura por "search_string" no arquivo chamado
filename. -
Pesquisar recursivamente em diretórios:
grep -r "search_string" /path/to/directoryEste comando procura por "
search_string"em todos os arquivos dentro do diretório especificado e seus subdiretórios. -
Ignorar maiúsculas e minúsculas durante a pesquisa:
grep -i "search_string" filenameEste comando executa uma pesquisa sem distinção entre maiúsculas e minúsculas para "search_string" no arquivo chamado
filename. -
Exibir números de linha com linhas correspondentes:
grep -n "search_string" filenameEste comando mostra os números das linhas junto com as linhas correspondentes no arquivo chamado
filename. -
Conte o número de linhas correspondentes:
grep -c "search_string" filenameEste comando conta o número de linhas que contêm "search_string" no arquivo chamado
filename. -
Inverta a correspondência para exibir as linhas que não correspondem:
grep -v "search_string" filenameEste comando exibe todas as linhas que não contêm "search_string" no arquivo chamado
filename. -
Pesquisar por uma palavra inteira:
grep -w "word" filenameEste comando procura a palavra "word" inteira no arquivo chamado
filename. -
Use expressões regulares estendidas:
grep -E "pattern" filenameEste comando permite o uso de expressões regulares estendidas para correspondência de padrões mais complexos no arquivo chamado
filename.
💡 Dica: Se houver vários arquivos em uma pasta, você pode usar o comando abaixo para encontrar a lista de arquivos que contêm as strings desejadas.
# find the list of files containing the desired strings
grep -l "String to Match" /path/to/directory
Extração de texto usando sed
sed significa "editor de fluxo". Ele processa dados por fluxo, ou seja, lê os dados uma linha de cada vez. sed Permite procurar padrões e executar ações nas linhas que correspondem a esses padrões.
Sintaxe básica desed :
A sintaxe básica de sed é a seguinte:
sed [options] 'command' file_name
Aqui, command é usado para realizar operações como substituição, exclusão, inserção e assim por diante, nos dados de texto. O nome do arquivo é o nome do arquivo que você deseja processar.
seduso:
1. Substituição:
A s bandeira é usada para substituir texto. O old-text é substituído por new-text:
sed 's/old-text/new-text/' filename
Por exemplo, para alterar todas as instâncias de "erro" para "aviso" no arquivo de log system.log:
sed 's/error/warning/' system.log
2. Imprimir linhas contendo um padrão específico:
Utilizando sed para filtrar e exibir linhas que correspondem a um padrão específico:
sed -n '/pattern/p' filename
Por exemplo, para encontrar todas as linhas que contêm "ERRO":
sed -n '/ERROR/p' system.log
3. Exclusão de linhas que contenham um padrão específico:
Você pode excluir linhas da saída que correspondem a um padrão específico:
sed '/pattern/d' filename
Por exemplo, para remover todas as linhas que contêm "DEBUG":
sed '/DEBUG/d' system.log
4. Extraindo campos específicos de uma linha de log:
Você pode usar expressões regulares para extrair partes de linhas. Suponha que cada linha do log comece com uma data no formato "AAAA-MM-DD". Você poderia extrair apenas a data de cada linha:
sed -n 's/^([0-9]{4}-[0-9]{2}-[0-9]{2}).*//p' system.log
Análise de texto com awk
awk tem a capacidade de dividir facilmente cada linha em campos. É adequado para processar texto estruturado, como arquivos de log.
Sintaxe básica deawk
A sintaxe básica de awk é:
awk 'pattern { action }' file_name
Aqui, pattern há uma condição que deve ser atendida para que a ação action seja executada. Se o padrão for omitido, a ação será executada em todas as linhas.
Nos próximos exemplos, você usará este arquivo de log como exemplo:
2024-04-25 09:00:00 INFO Startup: Application starting
2024-04-25 09:01:00 INFO Config: Configuration loaded successfully
2024-04-25 09:02:00 INFO Database: Database connection established
2024-04-25 09:03:00 INFO User: New user registered (UserID: 1001)
2024-04-25 09:04:00 INFO Security: Attempted login with incorrect credentials (UserID: 1001)
2024-04-25 09:05:00 INFO Network: Network timeout on request (ReqID: 456)
2024-04-25 09:06:00 INFO Email: Notification email sent (UserID: 1001)
2024-04-25 09:07:00 INFO API: API call with response time over threshold (Duration: 350ms)
2024-04-25 09:08:00 INFO Session: User session ended (UserID: 1001)
2024-04-25 09:09:00 INFO Shutdown: Application shutdown initiated
INFO
- Acessando colunas usando
awk
Os campos em awk (separados por espaços por padrão) podem ser acessados usando $1, $2, $3, e assim por diante.
zaira@zaira-ThinkPad:~$ awk '{ print $1 }' sample.log
# output
2024-04-25
2024-04-25
2024-04-25
2024-04-25
2024-04-25
2024-04-25
2024-04-25
2024-04-25
2024-04-25
2024-04-25
zaira@zaira-ThinkPad:~$ awk '{ print $2 }' sample.log
# output
09:00:00
09:01:00
09:02:00
09:03:00
09:04:00
09:05:00
09:06:00
09:07:00
09:08:00
09:09:00
- Imprimir linhas contendo um padrão específico (por exemplo, ERRO)
awk '/ERROR/ { print $0 }' logfile.log
# output
2024-04-25 09:05:00 ERROR Network: Network timeout on request (ReqID: 456)
Isso imprime todas as linhas que contêm "ERRO".
- Extraia o primeiro campo (Data e Hora)
awk '{ print $1, $2 }' logfile.log
# output
2024-04-25 09:00:00
2024-04-25 09:01:00
2024-04-25 09:02:00
2024-04-25 09:03:00
2024-04-25 09:04:00
2024-04-25 09:05:00
2024-04-25 09:06:00
2024-04-25 09:07:00
2024-04-25 09:08:007
2024-04-25 09:09:00
Isso extrairá os dois primeiros campos de cada linha, que neste caso seriam a data e a hora.
- Resumir ocorrências de cada nível de log
awk '{ count[$3]++ } END { for (level in count) print level, count[level] }' logfile.log
# output
1
WARN 1
ERROR 1
DEBUG 2
INFO 6
A saída será um resumo do número de ocorrências de cada nível de log.
- Filtrar campos específicos (por exemplo, onde o terceiro campo é INFO)
awk '{ $3="INFO"; print }' sample.log
# output
2024-04-25 09:00:00 INFO Startup: Application starting
2024-04-25 09:01:00 INFO Config: Configuration loaded successfully
2024-04-25 09:02:00 INFO Database: Database connection established
2024-04-25 09:03:00 INFO User: New user registered (UserID: 1001)
2024-04-25 09:04:00 INFO Security: Attempted login with incorrect credentials (UserID: 1001)
2024-04-25 09:05:00 INFO Network: Network timeout on request (ReqID: 456)
2024-04-25 09:06:00 INFO Email: Notification email sent (UserID: 1001)
2024-04-25 09:07:00 INFO API: API call with response time over threshold (Duration: 350ms)
2024-04-25 09:08:00 INFO Session: User session ended (UserID: 1001)
2024-04-25 09:09:00 INFO Shutdown: Application shutdown initiated
INFO
Este comando extrairá todas as linhas onde o terceiro campo for "INFO".
💡 Dica: O separador padrão awk é um espaço. Se o seu arquivo de log usar um separador diferente, você pode especificá-lo usando a -F opção . Por exemplo, se o seu arquivo de log usar dois pontos como separador, você pode usar awk -F: '{ print $1 }' logfile.log para extrair o primeiro campo.
Analisando arquivos de log com cut
O cut comando é simples, porém poderoso, usado para extrair seções de texto de cada linha de entrada. Como os arquivos de log são estruturados e cada campo é delimitado por um caractere específico, como um espaço, tabulação ou um delimitador personalizado, cut ele faz um ótimo trabalho na extração desses campos específicos.
A sintaxe básica do comando cut é:
cut [options] [file]
Algumas opções comumente usadas para o comando cut:
-
-d: Especifica um delimitador usado como separador de campo. -
-f: Seleciona os campos a serem exibidos. -
-c: Especifica posições de caracteres.
Por exemplo, o comando abaixo extrairia o primeiro campo (separado por um espaço) de cada linha do arquivo de log:
cut -d ' ' -f 1 logfile.log
Exemplos de uso cutpara análise de log
Suponha que você tenha um arquivo de log estruturado da seguinte forma, onde os campos são separados por espaços:
2024-04-25 08:23:01 INFO 192.168.1.10 User logged in successfully.
2024-04-25 08:24:15 WARNING 192.168.1.10 Disk usage exceeds 90%.
2024-04-25 08:25:02 ERROR 10.0.0.5 Connection timed out.
...
cut pode ser usado das seguintes maneiras:
- Extraindo o tempo de cada entrada de log :
cut -d ' ' -f 2 system.log
# Output
08:23:01
08:24:15
08:25:02
...
Este comando usa um espaço como delimitador e seleciona o segundo campo, que é o componente de tempo de cada entrada de log.
- Extraindo os endereços IP dos logs :
cut -d ' ' -f 4 system.log
# Output
192.168.1.10
192.168.1.10
10.0.0.5
Este comando extrai o quarto campo, que é o endereço IP de cada entrada de log.
- Extraindo níveis de log (INFO, WARNING, ERROR) :
cut -d ' ' -f 3 system.log
# Output
INFO
WARNING
ERROR
Isso extrai o terceiro campo que contém o nível de log.
- Combinando
cutcom outros comandos:
A saída de outros comandos pode ser canalizada para o cut comando. Digamos que você queira filtrar logs antes de cortar. Você pode usar grep para extrair linhas que contenham "ERROR" e, em seguida, usar cut para obter informações específicas dessas linhas:
grep "ERROR" system.log | cut -d ' ' -f 1,2
# Output
2024-04-25 08:25:02
Este comando primeiro filtra as linhas que incluem "ERROR" e depois extrai a data e a hora dessas linhas.
- Extraindo vários campos :
É possível extrair vários campos de uma só vez especificando um intervalo ou uma lista de campos separados por vírgulas:
cut -d ' ' -f 1,2,3 system.log`
# Output
2024-04-25 08:23:01 INFO
2024-04-25 08:24:15 WARNING
2024-04-25 08:25:02 ERROR
...
O comando acima extrai os três primeiros campos de cada entrada de log, que são data, hora e nível de log.
Analisando arquivos de log com sort e uniq
Classificar e remover duplicatas são operações comuns ao trabalhar com arquivos de log. Os comandos sort e uniq são comandos poderosos usados para classificar e remover duplicatas da entrada, respectivamente.
Sintaxe básica de classificação
O sort comando organiza linhas de texto em ordem alfabética ou numérica.
sort [options] [file]
Algumas opções importantes para o comando sort:
-
-n: Classifica o arquivo assumindo que o conteúdo é numérico. -
-r: Inverte a ordem de classificação. -
-k: Especifica uma chave ou número de coluna para classificação. -
-u: Classifica e remove linhas duplicadas.
O uniq comando é usado para filtrar ou contar e relatar linhas repetidas em um arquivo.
A sintaxe de uniq é:
uniq [options] [input_file] [output_file]
Algumas opções importantes para o uniq comando são:
-
-c: Prefixa as linhas pelo número de ocorrências. -
-d: Imprime somente linhas duplicadas. -
-u: Imprime somente linhas únicas.
Exemplos de uso sort e uniq juntos para análise de log
Vamos supor os seguintes exemplos de entradas de log para essas demonstrações:
2024-04-25 INFO User logged in successfully.
2024-04-25 WARNING Disk usage exceeds 90%.
2024-04-26 ERROR Connection timed out.
2024-04-25 INFO User logged in successfully.
2024-04-26 INFO Scheduled maintenance.
2024-04-26 ERROR Connection timed out.
- Classificando entradas de log por data :
sort system.log
# Output
2024-04-25 INFO User logged in successfully.
2024-04-25 INFO User logged in successfully.
2024-04-25 WARNING Disk usage exceeds 90%.
2024-04-26 ERROR Connection timed out.
2024-04-26 ERROR Connection timed out.
2024-04-26 INFO Scheduled maintenance.
Isso classifica as entradas de log em ordem alfabética, o que efetivamente as classifica por data se a data for o primeiro campo.
- Classificando e removendo duplicatas :
sort system.log | uniq
# Output
2024-04-25 INFO User logged in successfully.
2024-04-25 WARNING Disk usage exceeds 90%.
2024-04-26 ERROR Connection timed out.
2024-04-26 INFO Scheduled maintenance.
Este comando classifica o arquivo de log e o encaminha para uniq, removendo linhas duplicadas.
- Contagem de ocorrências de cada linha :
sort system.log | uniq -c
# Output
2 2024-04-25 INFO User logged in successfully.
1 2024-04-25 WARNING Disk usage exceeds 90%.
2 2024-04-26 ERROR Connection timed out.
1 2024-04-26 INFO Scheduled maintenance.
Classifica as entradas de log e conta cada linha exclusiva. De acordo com a saída, a linha '2024-04-25 INFO User logged in successfully.' apareceu 2 vezes no arquivo.
- Identificando entradas de log exclusivas :
sort system.log | uniq -u
# Output
2024-04-25 WARNING Disk usage exceeds 90%.
2024-04-26 INFO Scheduled maintenance.
Este comando mostra linhas que são únicas.
- Classificação por nível de log :
sort -k2 system.log
# Output
2024-04-26 ERROR Connection timed out.
2024-04-26 ERROR Connection timed out.
2024-04-25 INFO User logged in successfully.
2024-04-25 INFO User logged in successfully.
2024-04-26 INFO Scheduled maintenance.
2024-04-25 WARNING Disk usage exceeds 90%.
Classifica as entradas com base no segundo campo, que é o nível de log.
8.4. Gerenciando Processos Linux via Linha de Comando
Um processo é uma instância em execução de um programa. Um processo consiste em:
-
Um espaço de endereço da memória alocada.
-
Estados do processo.
-
Propriedades como propriedade, atributos de segurança e uso de recursos.
Um processo também tem um ambiente que consiste em:
-
Variáveis locais e globais
-
O contexto atual de agendamento
-
Recursos de sistema alocados, como portas de rede ou descritores de arquivo.
Ao executar o ls -l comando, o sistema operacional cria um novo processo para executá-lo. O processo tem um ID, um estado e é executado até que o comando seja concluído.
Compreendendo a criação e o ciclo de vida do processo
No Ubuntu, todos os processos se originam do processo inicial do sistema chamado systemd, que é o primeiro processo iniciado pelo kernel durante a inicialização.
O systemd processo tem um ID de processo (PID) de 1 e é responsável por inicializar o sistema, iniciar e gerenciar outros processos e gerenciar serviços do sistema. Todos os outros processos no sistema são descendentes de systemd.
Um processo pai duplica seu próprio espaço de endereço (bifurcação) para criar uma nova estrutura de processo (filho). Cada novo processo recebe um ID de processo (PID) exclusivo para fins de rastreamento e segurança. O PID e o ID de processo do pai (PPID) fazem parte do novo ambiente de processo. Qualquer processo pode criar um processo filho.
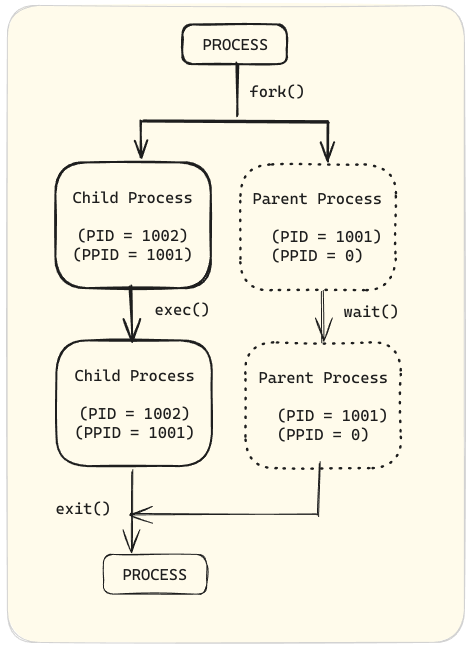
Por meio da rotina fork, um processo filho herda identidades de segurança, descritores de arquivo anteriores e atuais, privilégios de porta e recursos, variáveis de ambiente e código de programa. Um processo filho pode então executar seu próprio código de programa.
Normalmente, um processo pai dorme enquanto o processo filho é executado, definindo uma solicitação (espera) para ser notificado quando o processo filho for concluído.
Ao sair, o processo filho já fechou ou descartou seus recursos e ambiente. O único recurso restante, conhecido como zumbi, é uma entrada na tabela de processos. O processo pai, sinalizado como "acordado" quando o processo filho sai, limpa a tabela de processos da entrada do processo filho, liberando assim o último recurso do processo filho. O processo pai então continua executando seu próprio código de programa.
Compreendendo estados de processo
Os processos no Linux assumem diferentes estados ao longo de seu ciclo de vida. O estado de um processo indica o que ele está fazendo no momento e como está interagindo com o sistema. Os processos transitam entre estados com base em seu status de execução e no algoritmo de escalonamento do sistema.
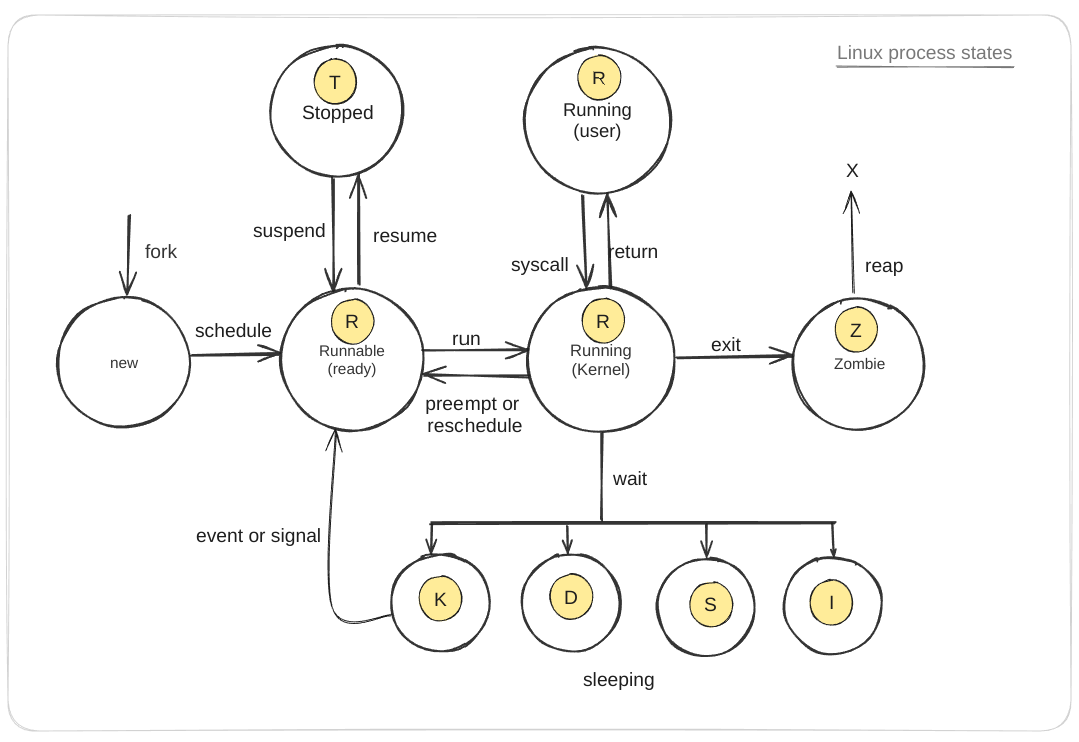
Os processos em um sistema Linux podem estar em um dos seguintes estados:
| Estado | Descrição |
| (novo) | Estado inicial quando um processo é criado por meio de uma chamada de sistema fork. |
| Executável (pronto) (R) | O processo está pronto para ser executado e aguardando para ser agendado em uma CPU. |
| Executando (usuário) (R) | O processo está sendo executado no modo de usuário, executando aplicativos de usuário. |
| Executando (kernel) (R) | O processo está sendo executado no modo kernel, manipulando chamadas de sistema ou interrupções de hardware. |
| Dormindo (S) | O processo está aguardando que um evento (por exemplo, uma operação de E/S) seja concluído e pode ser facilmente ativado. |
| Dormindo (ininterrupto) (D) | O processo está em um estado de hibernação ininterrupto, aguardando a conclusão de uma condição específica (geralmente E/S) e não pode ser interrompido por sinais. |
| Dormindo (dormindo em disco) (K) | O processo está aguardando a conclusão das operações de E/S do disco. |
| Dormindo (ocioso) (I) | O processo está ocioso, não realiza nenhum trabalho e aguarda a ocorrência de um evento. |
| Parado (T) | A execução do processo foi interrompida, normalmente por um sinal, e pode ser retomada mais tarde. |
| Zumbi (Z) | O processo concluiu a execução, mas ainda tem uma entrada na tabela de processos, aguardando que seu pai leia seu status de saída. |
Os processos de transição entre esses estados ocorrem das seguintes maneiras:
| Transição | Descrição |
| Garfo | Cria um novo processo a partir de um processo pai, fazendo a transição de (novo) para Executável (pronto) (R). |
| Agendar | O Agendador seleciona um processo executável, fazendo a transição para o estado Em execução (usuário) ou Em execução (kernel). |
| Correr | O processo passa de Executável (pronto) (R) para Em execução (kernel) (R) quando agendado para execução. |
| Antecipar ou Reprogramar | O processo pode ser interrompido ou reprogramado, voltando ao estado Executável (pronto) (R). |
| Chamada de sistema | O processo faz uma chamada de sistema, passando de Em execução (usuário) (R) para Em execução (kernel) (R). |
| Retornar | O processo conclui uma chamada de sistema e retorna para a execução (usuário) (R). |
| Espere | O processo aguarda um evento, passando de Em execução (kernel) (R) para um dos estados de suspensão (S, D, K ou I). |
| Evento ou Sinal | O processo é despertado por um evento ou sinal, movendo-o do estado de suspensão de volta para o estado Executável (pronto) (R). |
| Suspender | O processo é suspenso, passando de Em execução (kernel) ou Executável (pronto) para Parado (T). |
| Retomar | O processo é retomado, passando de Parado (T) para Executável (pronto) (R). |
| Saída | O processo termina, passando de Em execução (usuário) ou Em execução (kernel) para Zumbi (Z). |
| Colher | O processo pai lê o status de saída do processo zumbi, removendo-o da tabela de processos. |
Como visualizar processos
Você pode usar o ps comando junto com uma combinação de opções para visualizar processos em um sistema Linux. O ps comando é usado para exibir informações sobre uma seleção de processos ativos. Por exemplo, ps aux exibe todos os processos em execução no sistema.
zaira@zaira:~$ ps aux
# Output
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
root 1 0.0 0.0 168140 11352 ? Ss May21 0:18 /sbin/init splash
root 2 0.0 0.0 0 0 ? S May21 0:00 [kthreadd]
root 3 0.0 0.0 0 0 ? I< May21 0:00 [rcu_gp]
root 4 0.0 0.0 0 0 ? I< May21 0:00 [rcu_par_gp]
root 5 0.0 0.0 0 0 ? I< May21 0:00 [slub_flushwq]
root 6 0.0 0.0 0 0 ? I< May21 0:00 [netns]
root 11 0.0 0.0 0 0 ? I< May21 0:00 [mm_percpu_wq]
root 12 0.0 0.0 0 0 ? I May21 0:00 [rcu_tasks_kthread]
root 13 0.0 0.0 0 0 ? I May21 0:00 [rcu_tasks_rude_kthread]
*... output truncated ....*
A saída acima mostra um instantâneo dos processos em execução no sistema. Cada linha representa um processo com as seguintes colunas:
-
USER: O usuário que possui o processo. -
PID: O ID do processo. -
%CPU: O uso da CPU do processo. -
%MEM: O uso de memória do processo. -
VSZ: O tamanho da memória virtual do processo. -
RSS: O tamanho do conjunto residente, ou seja, a memória física não trocada que uma tarefa utilizou. -
TTY: O terminal de controle do processo. A?indica que não há terminal de controle. -
STAT: O estado do processo.-
R: Correndo -
IouS: Sono interrompível (esperando a conclusão de um evento) -
D: Sono ininterrupto (geralmente IO) -
T: Parado (por um sinal de controle de trabalho ou porque está sendo rastreado) -
Z: Zumbi (terminado, mas não colhido por seu pai) -
Ss: Líder de sessão. Este é um processo que iniciou uma sessão, é líder de um grupo de processos e pode controlar sinais de terminal. O primeiroSindica o estado de hibernação e o segundosindica que é um líder de sessão.
-
-
START: A hora ou data de início do processo. -
TIME: O tempo cumulativo da CPU. -
COMMAND: O comando que iniciou o processo.
Processos de primeiro e segundo plano
Nesta seção, você aprenderá como controlar trabalhos executando-os em segundo ou primeiro plano.
Uma tarefa é um processo iniciado por um shell. Quando você executa um comando no terminal, ele é considerado uma tarefa. Uma tarefa pode ser executada em primeiro ou segundo plano.
Para demonstrar controle, você primeiro criará três processos e os executará em segundo plano. Depois disso, você listará os processos e os alternará entre primeiro e segundo plano. Você verá como colocá-los em modo de espera ou encerrá-los completamente.
- Crie três processos
Abra um terminal e inicie três processos de longa duração. Use o sleep comando que mantém o processo em execução por um número especificado de segundos.
# run sleep command for 300, 400, and 500 seconds
sleep 300 &
sleep 400 &
sleep 500 &
O & no final de cada comando move o processo para segundo plano.
- Exibir trabalhos em segundo plano
Use o jobs comando para exibir a lista de trabalhos em segundo plano.
jobs
A saída deve ser algo como isto:
jobs
[1] Running sleep 300 &
[2]- Running sleep 400 &
[3]+ Running sleep 500 &
- Trazer um trabalho em segundo plano para o primeiro plano
Para trazer um trabalho em segundo plano para o primeiro plano, use o fg comando seguido do número do trabalho. Por exemplo, para trazer o primeiro trabalho ( sleep 300) para o primeiro plano:
fg %1
Isso colocará o emprego 1 em primeiro plano.
- Mover o trabalho em primeiro plano de volta para o segundo plano
Enquanto o trabalho estiver sendo executado em primeiro plano, você pode suspendê-lo e movê-lo de volta para o segundo plano pressionando Ctrl+Z para suspender o trabalho.
Um trabalho suspenso terá esta aparência:
zaira@zaira:~$ fg %1
sleep 300
^Z
[1]+ Stopped sleep 300
zaira@zaira:~$ jobs
# suspended job
[1]+ Stopped sleep 300
[2] Running sleep 400 &
[3]- Running sleep 500 &
Agora use o bg comando para retomar o trabalho com o ID 1 em segundo plano.
# Press Ctrl+Z to suspend the foreground job
# Then, resume it in the background
bg %1
- Exibir os trabalhos novamente
jobs
[1] Running sleep 300 &
[2]- Running sleep 400 &
[3]+ Running sleep 500 &
Neste exercício, você:
-
Iniciou três processos em segundo plano usando comandos de suspensão.
-
Trabalhos usados para exibir a lista de trabalhos em segundo plano.
-
Trouxe um trabalho para o primeiro plano com
fg %job_number. -
Suspendeu o trabalho com
Ctrl+Ze o moveu de volta para segundo plano combg %job_number. -
Usei os trabalhos novamente para verificar o status dos trabalhos em segundo plano.
Agora você sabe como controlar trabalhos.
Processos de eliminação
É possível encerrar um processo indesejado ou que não responde usando o kill comando. O kill comando envia um sinal para um ID de processo, solicitando que ele seja encerrado.
Várias opções estão disponíveis com o kill comando.
# Options available with kill
kill -l
1) SIGHUP 2) SIGINT 3) SIGQUIT 4) SIGILL 5) SIGTRAP
6) SIGABRT 7) SIGBUS 8) SIGFPE 9) SIGKILL 10) SIGUSR1
11) SIGSEGV 12) SIGUSR2 13) SIGPIPE 14) SIGALRM 15) SIGTERM
16) SIGSTKFLT 17) SIGCHLD 18) SIGCONT 19) SIGSTOP 20) SIGTSTP
21) SIGTTIN 22) SIGTTOU 23) SIGURG 24)
...terminated
Aqui estão alguns exemplos do kill comando no Linux:
-
Matar um processo por PID (ID do processo):
kill 1234Este comando envia o
SIGTERMsinal padrão para o processo com PID 1234, solicitando que ele seja encerrado. -
Matar um processo pelo nome:
pkill process_nameEste comando envia o
SIGTERMsinal padrão para todos os processos com o nome especificado. -
Matar um processo à força:
kill -9 1234Este comando envia o
SIGKILLsinal para o processo com PID 1234, encerrando-o à força. -
Enviar um sinal específico para um processo:
kill -s SIGSTOP 1234Este comando envia o
SIGSTOPsinal para o processo com PID 1234, interrompendo-o. -
Elimine todos os processos pertencentes a um usuário específico:
pkill -u usernameEste comando envia o
SIGTERMsinal padrão para todos os processos de propriedade do usuário especificado.
Esses exemplos demonstram várias maneiras de usar o kill comando para gerenciar processos em um ambiente Linux.
Aqui estão as informações sobre as kill opções de comando e sinais em forma de tabela: Esta tabela resume as kill opções de comando e sinais mais comuns usados no Linux para gerenciar processos.
| Comando / Opção | Sinal | Descrição |
kill <pid> |
SIGTERM |
Solicita que o processo seja encerrado corretamente (sinal padrão). |
kill -9 <pid> |
SIGKILL |
Força o processo a terminar imediatamente sem limpeza. |
kill -SIGKILL <pid> |
SIGKILL |
Força o processo a terminar imediatamente sem limpeza. |
kill -15 <pid> |
SIGTERM |
Envia explicitamente o SIGTERM sinal para solicitar o encerramento normal. |
kill -SIGTERM <pid> |
SIGTERM |
Envia explicitamente o SIGTERM sinal para solicitar o encerramento normal. |
kill -1 <pid> |
SIGHUP |
Tradicionalmente significa "desligar"; pode ser usado para recarregar arquivos de configuração. |
kill -SIGHUP <pid> |
SIGHUP |
Tradicionalmente significa "desligar"; pode ser usado para recarregar arquivos de configuração. |
kill -2 <pid> |
SIGINT |
Solicita que o processo seja encerrado (o mesmo que pressionar Ctrl+C no terminal). |
kill -SIGINT <pid> |
SIGINT |
Solicita que o processo seja encerrado (o mesmo que pressionar Ctrl+C no terminal). |
kill -3 <pid> |
SIGQUIT |
Faz com que o processo seja encerrado e produza um dump de memória para depuração. |
kill -SIGQUIT <pid> |
SIGQUIT |
Faz com que o processo seja encerrado e produza um dump de memória para depuração. |
kill -19 <pid> |
SIGSTOP |
Pausa o processo. |
kill -SIGSTOP <pid> |
SIGSTOP |
Pausa o processo. |
kill -18 <pid> |
SIGCONT |
Retoma um processo pausado. |
kill -SIGCONT <pid> |
SIGCONT |
Retoma um processo pausado. |
killall <name> |
Varia | Envia um sinal para todos os processos com o nome fornecido. |
killall -9 <name> |
SIGKILL |
Forçar a eliminação de todos os processos com o nome fornecido. |
pkill <pattern> |
Varia | Envia um sinal aos processos com base em uma correspondência de padrões. |
pkill -9 <pattern> |
SIGKILL |
Forçar mata todos os processos que correspondem ao padrão. |
xkill |
SIGKILL |
Utilitário gráfico que permite clicar em uma janela para matar o processo correspondente. |
8.5. Fluxos de entrada e saída padrão no Linux
Ler uma entrada e escrever uma saída é uma parte essencial da compreensão da linha de comando e do shell scripting. No Linux, cada processo tem três fluxos padrão:
-
Entrada Padrão (
stdin): Este fluxo é usado para entrada, normalmente do teclado. Quando um programa lê destdin, ele recebe dados inseridos pelo usuário ou redirecionados de um arquivo. Um descritor de arquivo é um identificador exclusivo que o sistema operacional atribui a um arquivo aberto para manter o controle dos arquivos abertos.O descritor de arquivo para
stdiné0. -
Saída Padrão (
stdout): Este é o fluxo de saída padrão onde um processo grava sua saída. Por padrão, a saída padrão é o terminal. A saída também pode ser redirecionada para um arquivo ou outro programa. O descritor de arquivo parastdouté1. -
Erro Padrão (
stderr): Este é o fluxo de erro padrão onde um processo grava suas mensagens de erro. Por padrão, o erro padrão é o terminal, permitindo que as mensagens de erro sejam visualizadas mesmo se o processostdoutfor redirecionado. O descritor de arquivo parastderré2.
Redirecionamento e Pipelines
Redirecionamento: Você pode redirecionar os fluxos de erro e saída para arquivos ou outros comandos. Por exemplo:
# Redirecting stdout to a file
ls > output.txt
# Redirecting stderr to a file
ls non_existent_directory 2> error.txt
# Redirecting both stdout and stderr to a file
ls non_existent_directory > all_output.txt 2>&1
No último comando,
-
ls non_existent_directory: lista o conteúdo de um diretório chamado diretório_não_existente. Como esse diretório não existe,lsserá gerada uma mensagem de erro. -
> all_output.txt: O>operador redireciona a saída padrão (stdout) dolscomando para o arquivoall_output.txt. Se o arquivo não existir, ele será criado. Se existir, seu conteúdo será sobrescrito. -
2>&1:: Aqui,2representa o descritor de arquivo para erro padrão (stderr).&1representa o descritor de arquivo para saída padrão (stdout). O&caractere é usado para especificar que1não é o nome do arquivo, mas um descritor de arquivo.
Portanto, 2>&1 significa "redirecionar stderr(2) para onde stdout(1) estiver indo", que neste caso é o arquivo all_output.txt. Portanto, tanto a saída (se houver) quanto a mensagem de erro de ls serão gravadas em all_output.txt.
Gasodutos:
Você pode usar pipes ( |) para passar a saída de um comando como entrada para outro:
ls | grep image
# Output
image-10.png
image-11.png
image-12.png
image-13.png
... Output truncated ...
8.6 Automação no Linux – Automatize tarefas com Cron Jobs
O Cron é um utilitário poderoso para agendamento de tarefas, disponível em sistemas operacionais do tipo Unix. Ao configurar o cron, você pode configurar tarefas automatizadas para execução diária, semanal, mensal ou em outro período específico. Os recursos de automação fornecidos pelo cron desempenham um papel crucial na administração de sistemas Linux.
O crond daemon (um tipo de programa de computador executado em segundo plano) habilita a funcionalidade do cron. O cron lê o crontab (tabelas do cron) para executar scripts predefinidos.
Usando uma sintaxe específica, você pode configurar uma tarefa cron para agendar scripts ou outros comandos para serem executados automaticamente.
O que são tarefas cron no Linux?
Qualquer tarefa que você agenda por meio do crons é chamada de tarefa cron.
Agora, vamos ver como funcionam as tarefas cron.
Como controlar o acesso aos crons
Para usar tarefas cron, um administrador precisa permitir que tarefas cron sejam adicionadas para usuários no /etc/cron.allow arquivo.
Se você receber um prompt como esse, significa que você não tem permissão para usar o cron.
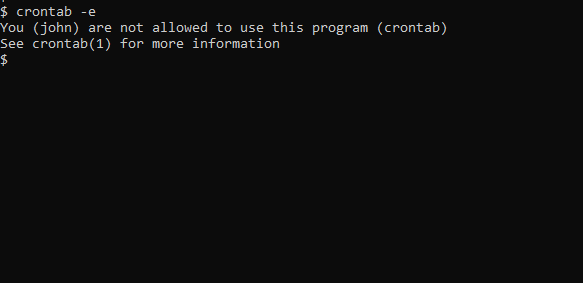
Para permitir que John use crons, inclua o nome dele em /etc/cron.allow. Crie o arquivo se ele não existir. Isso permitirá que John crie e edite tarefas cron.
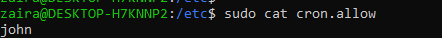
Os usuários também podem ter o acesso ao trabalho cron negado ao inserir seus nomes de usuário no arquivo /etc/cron.d/cron.deny .
Como adicionar tarefas cron no Linux
Primeiro, para usar tarefas do cron, você precisa verificar o status do serviço cron. Se o cron não estiver instalado, você pode baixá-lo facilmente pelo gerenciador de pacotes. Basta usar isto para verificar:
# Check cron service on Linux system
sudo systemctl status cron.service
Sintaxe da tarefa Cron
Os crontabs usam os seguintes sinalizadores para adicionar e listar tarefas cron:
-
crontab -e: edita entradas do crontab para adicionar, excluir ou editar tarefas cron. -
crontab -l: lista todas as tarefas cron do usuário atual. -
crontab -u username -l: listar crons de outro usuário. -
crontab -u username -e: editar crons de outro usuário.
Quando você lista crons e eles existem, você verá algo assim:
# Cron job example
* * * * * sh /path/to/script.sh
No exemplo acima,
*representa minuto(s), hora(s), dia(s), mês(es) e dia(s) da semana, respectivamente. Veja os detalhes desses valores abaixo:
| VALOR | DESCRIÇÃO | |
| Minutos | 0-59 | O comando será executado no minuto específico. |
| Horas | 0-23 | O comando será executado na hora específica. |
| Dias | 1-31 | Os comandos serão executados nestes dias dos meses. |
| Meses | 1-12 | O mês em que as tarefas precisam ser executadas. |
| Dias da semana | 0-6 | Dias da semana em que os comandos serão executados. Aqui, 0 é domingo. |
-
shrepresenta que o script é um script bash e deve ser executado a partir de/bin/bash. -
/path/to/script.shespecifica o caminho para o script.
Abaixo está um resumo da sintaxe do cron job:
* * * * * sh /path/to/script/script.sh
| | | | | |
| | | | | Command or Script to Execute
| | | | |
| | | | |
| | | | |
| | | | Day of the Week(0-6)
| | | |
| | | Month of the Year(1-12)
| | |
| | Day of the Month(1-31)
| |
| Hour(0-23)
|
Min(0-59)
Exemplos de tarefas cron
Abaixo estão alguns exemplos de agendamento de tarefas cron.
| AGENDAR | VALOR AGENDADO |
5 0 * 8 * |
Às 00:05 de agosto. |
5 4 * * 6 |
Às 04:05 de sábado. |
0 22 * * 1-5 |
Às 22:00, todos os dias da semana, de segunda a sexta-feira. |
Não tem problema se você não conseguir entender tudo isso de uma vez. Você pode praticar e gerar agendamentos cron com o site crontab guru .
Como configurar uma tarefa cron
Nesta seção, veremos um exemplo de como agendar um script simples com uma tarefa cron.
- Crie um script chamado
date-script.sh, que imprime a data e a hora do sistema e as anexa a um arquivo. O script é mostrado abaixo:
#!/bin/bash
echo `date` >> date-out.txt
2. Torne o script executável concedendo a ele direitos de execução.
chmod 775 date-script.sh
3. Adicione o script no crontab usando crontab -e.
Aqui, programamos para ser executado por minuto.
*/1 * * * * /bin/sh /root/date-script.sh
4. Verifique a saída do arquivo date-out.txt. De acordo com o script, a data do sistema deve ser impressa neste arquivo a cada minuto.
cat date-out.txt
# output
Wed 26 Jun 16:59:33 PKT 2024
Wed 26 Jun 17:00:01 PKT 2024
Wed 26 Jun 17:01:01 PKT 2024
Wed 26 Jun 17:02:01 PKT 2024
Wed 26 Jun 17:03:01 PKT 2024
Wed 26 Jun 17:04:01 PKT 2024
Wed 26 Jun 17:05:01 PKT 2024
Wed 26 Jun 17:06:01 PKT 2024
Wed 26 Jun 17:07:01 PKT 2024
Como solucionar problemas de crons
Crons são realmente úteis, mas nem sempre funcionam como o esperado. Felizmente, existem alguns métodos eficazes que você pode usar para solucioná-los.
1. Verifique a programação.
Primeiro, você pode tentar verificar o agendamento definido para o cron. Você pode fazer isso com a sintaxe que viu nas seções acima.
2. Verifique os logs do cron .
Primeiro, você precisa verificar se o cron foi executado no horário previsto ou não. No Ubuntu, você pode verificar isso nos logs do cron localizados em /var/log/syslog.
Se houver uma entrada nesses logs no horário correto, significa que o cron foi executado de acordo com o agendamento definido.
Abaixo estão os logs do nosso exemplo de tarefa cron. Observe a primeira coluna que mostra o registro de data e hora. O caminho do script também é mencionado no final da linha. As linhas 1, 3 e 5 mostram que o script foi executado conforme o esperado.
1 Jun 26 17:02:01 zaira-ThinkPad CRON[27834]: (zaira) CMD (/bin/sh /home/zaira/date-script.sh)
2 Jun 26 17:02:02 zaira-ThinkPad systemd[2094]: Started Tracker metadata extractor.
3 Jun 26 17:03:01 zaira-ThinkPad CRON[28255]: (zaira) CMD (/bin/sh /home/zaira/date-script.sh)
4 Jun 26 17:03:02 zaira-ThinkPad systemd[2094]: Started Tracker metadata extractor.
5 Jun 26 17:04:01 zaira-ThinkPad CRON[28538]: (zaira) CMD (/bin/sh /home/zaira/date-script.sh)
3. Redirecione a saída do cron para um arquivo.
Você pode redirecionar a saída de um cron para um arquivo e verificar se há possíveis erros no arquivo.
# Redirect cron output to a file
* * * * * sh /path/to/script.sh &> log_file.log
8.7. Noções básicas de rede Linux
O Linux oferece diversos comandos para visualizar informações relacionadas à rede. Nesta seção, discutiremos brevemente alguns desses comandos.
Exibir interfaces de rede com ifconfig
O ifconfig comando fornece informações sobre interfaces de rede. Aqui está um exemplo de saída:
ifconfig
# Output
eth0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 192.168.1.100 netmask 255.255.255.0 broadcast 192.168.1.255
inet6 fe80::a00:27ff:fe4e:66a1 prefixlen 64 scopeid 0x20<link>
ether 08:00:27:4e:66:a1 txqueuelen 1000 (Ethernet)
RX packets 1024 bytes 654321 (654.3 KB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 512 bytes 123456 (123.4 KB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
lo: flags=73<UP,LOOPBACK,RUNNING> mtu 65536
inet 127.0.0.1 netmask 255.0.0.0
inet6 ::1 prefixlen 128 scopeid 0x10<host>
loop txqueuelen 1000 (Local Loopback)
RX packets 256 bytes 20480 (20.4 KB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 256 bytes 20480 (20.4 KB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
A saída do ifconfig comando mostra as interfaces de rede configuradas no sistema, juntamente com detalhes como endereços IP, endereços MAC, estatísticas de pacotes e muito mais.
Essas interfaces podem ser dispositivos físicos ou virtuais.
Para extrair endereços IPv4 e IPv6, você pode usar ip -4 addr e ip -6 addr, respectivamente.
Ver atividade de rede comnetstat
O netstat comando mostra a atividade e estatísticas da rede fornecendo as seguintes informações:
Aqui estão alguns exemplos de uso do netstat comando na linha de comando:
-
Exibir todos os soquetes de escuta e não escuta:
netstat -a -
Mostrar apenas portas de escuta:
netstat -l -
Exibir estatísticas da rede:
netstat -s -
Mostrar tabela de roteamento:
netstat -r -
Exibir conexões TCP:
netstat -t -
Exibir conexões UDP:
netstat -u -
Mostrar interfaces de rede:
netstat -i -
Exibir nomes de PID e programas para conexões:
netstat -p -
Mostrar estatísticas para um protocolo específico (por exemplo, TCP):
netstat -st -
Exibir informações estendidas:
netstat -e
Verifique a conectividade de rede entre dois dispositivos usando ping
ping É usado para testar a conectividade de rede entre dois dispositivos. Ele envia pacotes ICMP para o dispositivo de destino e aguarda uma resposta.
ping google.com
ping testa se você obtém uma resposta sem atingir um tempo limite.
ping google.com
PING google.com (142.250.181.46) 56(84) bytes of data.
64 bytes from fjr04s06-in-f14.1e100.net (142.250.181.46): icmp_seq=1 ttl=60 time=78.3 ms
64 bytes from fjr04s06-in-f14.1e100.net (142.250.181.46): icmp_seq=2 ttl=60 time=141 ms
64 bytes from fjr04s06-in-f14.1e100.net (142.250.181.46): icmp_seq=3 ttl=60 time=205 ms
64 bytes from fjr04s06-in-f14.1e100.net (142.250.181.46): icmp_seq=4 ttl=60 time=100 ms
^C
--- google.com ping statistics ---
4 packets transmitted, 4 received, 0% packet loss, time 3001ms
rtt min/avg/max/mdev = 78.308/131.053/204.783/48.152 ms
Você pode parar a resposta com Ctrl + C.
Testando endpoints com o curl comando
O curl comando significa "URL do cliente". É usado para transferir dados de ou para um servidor. Também pode ser usado para testar endpoints de API, o que ajuda a solucionar erros de sistema e de aplicativos.
Como exemplo, você pode usar http://www.official-joke-api.appspot.com/ para experimentar o curl comando.
- O
curlcomando sem nenhuma opção usa o método GET por padrão.
curl http://www.official-joke-api.appspot.com/random_joke
{"type":"general",
"setup":"What did the fish say when it hit the wall?","punchline":"Dam.","id":1}
curl -osalva a saída no arquivo mencionado.
curl -o random_joke.json http://www.official-joke-api.appspot.com/random_joke
# saves the output to random_joke.json
curl -Ibusca apenas os cabeçalhos.
curl -I http://www.official-joke-api.appspot.com/random_joke
HTTP/1.1 200 OK
Content-Type: application/json; charset=utf-8
Vary: Accept-Encoding
X-Powered-By: Express
Access-Control-Allow-Origin: *
ETag: W/"71-NaOSpKuq8ChoxdHD24M0lrA+JXA"
X-Cloud-Trace-Context: 2653a86b36b8b131df37716f8b2dd44f
Content-Length: 113
Date: Thu, 06 Jun 2024 10:11:50 GMT
Server: Google Frontend
8.8. Solução de problemas do Linux: ferramentas e técnicas
Relatório de atividade do sistema com sar
O sar comando no Linux é uma ferramenta poderosa para coletar, relatar e salvar informações sobre a atividade do sistema. Faz parte do sysstat pacote e é amplamente utilizado para monitorar o desempenho do sistema ao longo do tempo.
Para usar sar você primeiro precisa instalar syssstat usando sudo apt install sysstat .
Uma vez instalado, inicie o serviço com sudo systemctl start sysstat .
Verifique o status com sudo systemctl status sysstat .
Assim que o status estiver ativo, o sistema começará a coletar diversas estatísticas que você poderá usar para acessar e analisar dados históricos. Veremos isso em detalhes em breve.
A sintaxe do sar comando é a seguinte:
sar [options] [interval] [count]
Por exemplo, sar -u 1 3 exibirá estatísticas de utilização da CPU a cada segundo, três vezes.
sar -u 1 3
# Output
Linux 6.5.0-28-generic (zaira-ThinkPad) 04/06/24 _x86_64_ (12 CPU)
19:09:26 CPU %user %nice %system %iowait %steal %idle
19:09:27 all 3.78 0.00 2.18 0.08 0.00 93.96
19:09:28 all 4.02 0.00 2.01 0.08 0.00 93.89
19:09:29 all 6.89 0.00 2.10 0.00 0.00 91.01
Average: all 4.89 0.00 2.10 0.06 0.00 92.95
Aqui estão alguns casos de uso comuns e exemplos de como usar o sar comando.
sar pode ser usado para uma variedade de propósitos:
1. Uso de memória
Para verificar o uso da memória (livre e usada), use:
sar -r 1 3
Linux 6.5.0-28-generic (zaira-ThinkPad) 04/06/24 _x86_64_ (12 CPU)
19:10:46 kbmemfree kbavail kbmemused %memused kbbuffers kbcached kbcommit %commit kbactive kbinact kbdirty
19:10:47 4600104 8934352 5502124 36.32 375844 4158352 15532012 65.99 6830564 2481260 264
19:10:48 4644668 8978940 5450252 35.98 375852 4165648 15549184 66.06 6776388 2481284 36
19:10:49 4646548 8980860 5448328 35.97 375860 4165648 15549224 66.06 6774368 2481292 116
Average: 4630440 8964717 5466901 36.09 375852 4163216 15543473 66.04 6793773 2481279 139
Este comando exibe estatísticas de memória três vezes a cada segundo.
2. Trocar a utilização do espaço
Para visualizar estatísticas de utilização do espaço de swap, use:
sar -S 1 3
sar -S 1 3
Linux 6.5.0-28-generic (zaira-ThinkPad) 04/06/24 _x86_64_ (12 CPU)
19:11:20 kbswpfree kbswpused %swpused kbswpcad %swpcad
19:11:21 8388604 0 0.00 0 0.00
19:11:22 8388604 0 0.00 0 0.00
19:11:23 8388604 0 0.00 0 0.00
Average: 8388604 0 0.00 0 0.00
Este comando ajuda a monitorar o uso de swap, o que é crucial para sistemas que ficam sem memória física.
3. Carga de dispositivos de E/S
Para relatar atividade para dispositivos de bloco e partições de dispositivos de bloco:
sar -d 1 3
Este comando fornece estatísticas detalhadas sobre transferências de dados de e para dispositivos de bloco e é útil para diagnosticar gargalos de E/S.
5. Estatísticas de rede
Para visualizar estatísticas de rede, como número de pacotes recebidos (transmitidos) pela interface de rede:
sar -n DEV 1 3
# -n DEV tells sar to report network device interfaces
sar -n DEV 1 3
Linux 6.5.0-28-generic (zaira-ThinkPad) 04/06/24 _x86_64_ (12 CPU)
19:12:47 IFACE rxpck/s txpck/s rxkB/s txkB/s rxcmp/s txcmp/s rxmcst/s %ifutil
19:12:48 lo 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
19:12:48 enp2s0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
19:12:48 wlp3s0 10.00 3.00 1.83 0.37 0.00 0.00 0.00 0.00
19:12:48 br-5129d04f972f 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
.
.
.
Average: IFACE rxpck/s txpck/s rxkB/s txkB/s rxcmp/s txcmp/s rxmcst/s %ifutil
Average: lo 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
Average: enp2s0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
...output truncated...
Isso exibe estatísticas de rede a cada segundo durante três segundos, ajudando no monitoramento do tráfego de rede.
6. Dados históricos
Lembre-se de que instalamos o sysstat pacote e executamos o serviço anteriormente. Siga os passos abaixo para habilitar e acessar os dados históricos.
-
Habilitar coleta de dados: edite o
sysstatarquivo de configuração para habilitar a coleta de dados.sudo nano /etc/default/sysstatAlterar
ENABLED="false"paraENABLED="true".vim /etc/default/sysstat # # Default settings for /etc/init.d/sysstat, /etc/cron.d/sysstat # and /etc/cron.daily/sysstat files # # Should sadc collect system activity informations? Valid values # are "true" and "false". Please do not put other values, they # will be overwritten by debconf! ENABLED="true" -
Configurar intervalo de coleta de dados: edite a configuração do cron job para definir o intervalo de coleta de dados.
sudo nano /etc/cron.d/sysstatPor padrão, ele coleta dados a cada 10 minutos. Você pode ajustar o intervalo modificando o agendamento da tarefa cron. Os arquivos relevantes serão enviados para a
/var/log/sysstatpasta. -
Visualizar dados históricos: use o
sarcomando para visualizar dados históricos. Por exemplo, para visualizar o uso da CPU no dia atual:sar -uPara visualizar dados de uma data específica:
sar -u -f /var/log/sysstat/sa<DD>Substitua
<DD>pelo dia do mês cujos dados você deseja visualizar.O comando abaixo
/var/log/sysstat/sa04fornece estatísticas para o 4º dia do mês atual.
sar -u -f /var/log/sysstat/sa04
Linux 6.5.0-28-generic (zaira-ThinkPad) 04/06/24 _x86_64_ (12 CPU)
15:20:49 LINUX RESTART (12 CPU)
16:13:30 LINUX RESTART (12 CPU)
18:16:00 CPU %user %nice %system %iowait %steal %idle
18:16:01 all 0.25 0.00 0.67 0.08 0.00 99.00
Average: all 0.25 0.00 0.67 0.08 0.00 99.00
7. Interrupções de CPU em tempo real
Para observar interrupções em tempo real por segundo atendidas pela CPU, use este comando:
sar -I SUM 1 3
# Output
Linux 6.5.0-28-generic (zaira-ThinkPad) 04/06/24 _x86_64_ (12 CPU)
19:14:22 INTR intr/s
19:14:23 sum 5784.00
19:14:24 sum 5694.00
19:14:25 sum 5795.00
Average: sum 5757.67
Este comando ajuda a monitorar a frequência com que a CPU está lidando com interrupções, o que pode ser crucial para o ajuste de desempenho em tempo real.
Estes exemplos ilustram como você pode usar o sar para monitorar vários aspectos do desempenho do sistema. O uso regular do sar pode ajudar a identificar gargalos no sistema e garantir que os aplicativos continuem funcionando com eficiência.
8.9. Estratégia geral de solução de problemas para servidores
Por que precisamos entender o monitoramento?
O monitoramento do sistema é um aspecto importante da administração de sistemas. Aplicações críticas exigem um alto nível de proatividade para prevenir falhas e reduzir o impacto de interrupções.
O Linux oferece ferramentas muito poderosas para avaliar a saúde do sistema. Nesta seção, você aprenderá sobre os vários métodos disponíveis para verificar a saúde do seu sistema e identificar gargalos.
Encontre a média de carga e o tempo de atividade do sistema
Podem ocorrer reinicializações do sistema, o que às vezes pode bagunçar algumas configurações. Para verificar há quanto tempo a máquina está ativa, use o comando: uptime. Além do tempo de atividade, o comando também exibe a média de carga.
[user@host ~]$ uptime 19:15:00 up 1:04, 0 users, load average: 2.92, 4.48, 5.20
A carga média é a carga do sistema nos últimos 1, 5 e 15 minutos. Uma rápida olhada indica se a carga do sistema parece estar aumentando ou diminuindo ao longo do tempo.
Observação: A fila ideal da CPU é 0. Isso só é possível quando não há filas de espera para a CPU.
A carga por CPU pode ser calculada dividindo a média de carga pelo número total de CPUs disponíveis.
Para encontrar o número de CPUs, use o comando lscpu.
lscpu
# output
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Address sizes: 48 bits physical, 48 bits virtual
Byte Order: Little Endian
CPU(s): 12
On-line CPU(s) list: 0-11
.
.
.
output omitted
Se a carga média parece aumentar e não diminui, as CPUs estão sobrecarregadas. Há algum processo travado ou há um vazamento de memória.
Calculando memória livre
Às vezes, a alta utilização da memória pode estar causando problemas. Para verificar a memória disponível e a memória em uso, use o free comando .
free -mh
# output
total used free shared buff/cache available
Mem: 14Gi 3.5Gi 7.7Gi 109Mi 3.2Gi 10Gi
Swap: 8.0Gi 0B 8.0Gi
Calculando espaço em disco
Para garantir a integridade do sistema, não se esqueça do espaço em disco. Para listar todos os pontos de montagem disponíveis e suas respectivas porcentagens de uso, use o comando abaixo. O ideal é que o espaço em disco utilizado não exceda 80%.
O df comando fornece espaços em disco detalhados.
df -h
Filesystem Size Used Avail Use% Mounted on
tmpfs 1.5G 2.4M 1.5G 1% /run
/dev/nvme0n1p2 103G 34G 65G 35% /
tmpfs 7.3G 42M 7.2G 1% /dev/shm
tmpfs 5.0M 4.0K 5.0M 1% /run/lock
efivarfs 246K 93K 149K 39% /sys/firmware/efi/efivars
/dev/nvme0n1p3 130G 47G 77G 39% /home
/dev/nvme0n1p1 511M 6.1M 505M 2% /boot/efi
tmpfs 1.5G 140K 1.5G 1% /run/user/1000
Determinando estados do processo
Os estados dos processos podem ser monitorados para verificar qualquer processo travado com alto uso de memória ou CPU.
Vimos anteriormente que o ps comando fornece informações úteis sobre um processo. Dê uma olhada nas colunas CPU e .MEM
[user@host ~]$ ps aux
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
runner 1 0.1 0.0 1535464 15576 ? S 19:18 0:00 /inject/init
runner 14 0.0 0.0 21484 3836 pts/0 S 19:21 0:00 bash --norc
runner 22 0.0 0.0 37380 3176 pts/0 R+ 19:23 0:00 ps aux
Monitoramento do sistema em tempo real
O monitoramento em tempo real fornece uma janela para o estado do sistema em tempo real.
Um utilitário que você pode usar para fazer isso é o top comando.
O comando top exibe uma visão dinâmica dos processos do sistema, exibindo um cabeçalho de resumo seguido por uma lista de processos ou threads. Ao contrário de sua contraparte estática ps, o comando top top atualiza continuamente as estatísticas do sistema.
Com top, você pode ver detalhes bem organizados em uma janela compacta. Há uma série de sinalizadores, atalhos e métodos de destaque que acompanham top.
Você também pode encerrar processos usando top. Para isso, pressione k e digite o ID do processo.
Interpretando registros
Os logs do sistema e dos aplicativos contêm inúmeras informações sobre o que o sistema está passando. Eles contêm informações úteis e códigos de erro que apontam para erros. Se você procurar por códigos de erro nos logs, o tempo de identificação e correção de problemas pode ser bastante reduzido.
Análise de portas de rede
O aspecto da rede não deve ser ignorado, pois falhas de rede são comuns e podem impactar o sistema e o fluxo de tráfego. Problemas comuns de rede incluem exaustão de portas, bloqueio de portas, recursos não liberados, entre outros.
Para identificar esses problemas, precisamos entender os estados dos portos.
Alguns dos estados portuários são explicados brevemente aqui:
| Estado | Descrição |
| OUVIR | Representa portas que estão aguardando uma solicitação de conexão de qualquer porta TCP remota. |
| ESTABELECIDO | Representa conexões que estão abertas e os dados recebidos podem ser entregues ao destino. |
| TEMPO DE ESPERA | Representa o tempo de espera para garantir o reconhecimento da solicitação de encerramento da conexão. |
| FIM ESPERE2 | Representa a espera de uma solicitação de término de conexão do TCP remoto. |
Vamos explorar como podemos analisar informações relacionadas a portas no Linux.
Intervalos de portas: Os intervalos de portas são definidos no sistema e podem ser aumentados/diminuídos conforme necessário. No trecho abaixo, o intervalo é de 1 15000 a 10 65000, o que totaliza 50000 (65.000 a 15.000) portas disponíveis. Se as portas utilizadas estiverem atingindo ou excedendo esse limite, há um problema.
[user@host ~]$ /sbin/sysctl net.ipv4.ip_local_port_range
net.ipv4.ip_local_port_range = 15000 65000
O erro relatado nos logs nesses casos pode ser Failed to bind to port ou Too many connections.
Identificando perda de pacotes
No monitoramento do sistema, precisamos garantir que a comunicação de entrada e saída esteja intacta.
Um comando útil é ping. ping atinge o sistema de destino e retorna a resposta. Observe as últimas linhas de estatísticas que mostram a porcentagem e o tempo de perda de pacotes.
# ping destination IP
[user@host ~]$ ping 10.13.6.113
PING 10.13.6.141 (10.13.6.141) 56(84) bytes of data.
64 bytes from 10.13.6.113: icmp_seq=1 ttl=128 time=0.652 ms
64 bytes from 10.13.6.113: icmp_seq=2 ttl=128 time=0.593 ms
64 bytes from 10.13.6.113: icmp_seq=3 ttl=128 time=0.478 ms
64 bytes from 10.13.6.113: icmp_seq=4 ttl=128 time=0.384 ms
64 bytes from 10.13.6.113: icmp_seq=5 ttl=128 time=0.432 ms
64 bytes from 10.13.6.113: icmp_seq=6 ttl=128 time=0.747 ms
64 bytes from 10.13.6.113: icmp_seq=7 ttl=128 time=0.379 ms
^C
--- 10.13.6.113 ping statistics ---
7 packets transmitted, 7 received,0% packet loss, time 6001ms
rtt min/avg/max/mdev = 0.379/0.523/0.747/0.134 ms
Pacotes também podem ser capturados em tempo de execução usando tcpdump. Veremos isso mais tarde.
Coletando estatísticas para o problema post mortem
É sempre uma boa prática coletar certas estatísticas que seriam úteis para identificar a causa raiz posteriormente. Normalmente, após a reinicialização do sistema ou dos serviços, perdemos o instantâneo e os logs anteriores do sistema.
Abaixo estão alguns métodos para capturar um instantâneo do sistema.
- Backup de logs
Antes de fazer qualquer alteração, copie os arquivos de log para outro arquivo . Isso é crucial para entender em que condição o sistema estava no momento do problema. Às vezes, os arquivos de log são a única janela para visualizar estados anteriores do sistema, pois outras estatísticas de tempo de execução são perdidas.
- Despejo TCP
Tcpdump é um utilitário de linha de comando que permite capturar e analisar o tráfego de entrada e saída da rede. É usado principalmente para ajudar a solucionar problemas de rede. Se você acha que o tráfego do sistema está sendo afetado, siga tcpdump as instruções abaixo:
sudo tcpdump -i any -w
# Where,
# -i any captures traffic from all interfaces
# -w specifies the output filename
# Stop the command after a few mins as the file size may increase
# use file extension as .pcap
Depois tcpdump de capturado, você pode usar ferramentas como o Wireshark para analisar visualmente o tráfego.
8.10 Diagnosticando problemas de hardware
Solucionar problemas inesperados faz parte do processo de aprendizagem. Às vezes, você pode notar falhas de segmentação frequentes ( SIGSEGV), superaquecimento ou travamentos aleatórios em aplicativos não relacionados. O problema pode estar relacionado a software ou hardware. Embora os problemas relacionados a software dependam do aplicativo específico em si, os problemas de hardware podem ser diagnosticados com algumas etapas padrão.
Nesta seção, discutiremos como diagnosticar e descartar problemas de hardware relacionados à memória, CPU, sensores do sistema, fonte de alimentação e muito mais.
8.10.1 Analisando o desempenho da memória
Determinar a RAM disponível
Se você perceber que seu sistema está ficando lento e demorando mais para concluir tarefas, verifique a memória disponível. Isso garantirá que haja memória suficiente, incluindo a memória swap.
O comando para verificar a memória disponível é free -mh, onde -h é para saída legível e -m é para exibir a memória em MB.
free -mh
total used free shared buff/cache available
Mem: 14Gi 5.1Gi 2.4Gi 77Mi 7.3Gi 9.3Gi
Swap: 4.0Gi 0B 4.0Gi
Na saída acima, observe a coluna "disponível" na linha "Memória". Ela mostra quanta RAM está livre para uso.
Outra maneira de verificar a memória em tempo real é usar o top comando . Há duas maneiras de fazer isso:
-
Quando estiver em
top, pressioneShift + Mpara classificar os processos por uso de memória. -
Alternativamente, pressione
mpara ver o uso da memória em uma barra de progresso como formato:

Se você observar que a memória está sendo consumida próximo a 100%, considere identificar o processo que está consumindo a memória e tomar as medidas necessárias. Você também pode considerar adicionar mais memória ao seu sistema.
Execute um teste de estresse no seu hardware
O memtester comando é um utilitário usado para diagnosticar problemas relacionados à memória, sobrecarregando-a e verificando se há falhas. É frequentemente usado em situações em que você suspeita que uma RAM defeituosa pode estar causando instabilidade ou travamentos do sistema.
Veja como usá-lo de forma eficaz:
-
Primeiro, instale
memtester.sudo apt install memtester -
Determine a quantidade de RAM a ser testada e o número de passagens pelas quais você deseja que sua RAM passe. No comando abaixo,
1Gé a quantidade de RAM a ser testada (1 GB) e5é o número de passagens de teste:sudo memtester 1G 5
Se todos os testes forem aprovados, sua RAM provavelmente estará livre de erros. Se forem relatados erros, sua RAM pode estar com defeito e precisar ser substituída ou inspecionada novamente. Você sempre pode executar o teste novamente com uma quantidade diferente de RAM ou o teste será aprovado.
Observe que você não deve testar muita memória de uma só vez, pois seu sistema também precisa de memória para executar processos. Se você tiver mais RAM do que pode ser testado de uma só vez, teste em segmentos menores sequencialmente.
Abaixo está um trecho da memtester saída caso todos os testes sejam aprovados. Observe o ”ok” status de cada teste.
memtester version 4.5.1 (64-bit)
Copyright (C) 2001-2020 Charles Cazabon.
Licensed under the GNU General Public License version 2 (only).
pagesize is 4096
pagesizemask is 0xfffffffffffff000
want 1024MB (1073741824 bytes)
got 1024MB (1073741824 bytes), trying mlock ...locked.
Loop 1/5:
Stuck Address : ok
Random Value : ok
Compare XOR : ok
Compare SUB : ok
Compare MUL : ok
Compare DIV : ok
Compare OR : ok
Compare AND : ok
Sequential Increment: ok
Solid Bits : ok
Block Sequential : ok
Checkerboard : ok
Bit Spread : ok
Bit Flip : ok
Walking Ones : ok
Walking Zeroes : ok
8-bit Writes : ok
16-bit Writes : ok
.
.
.
Abaixo está um trecho da saída caso um teste falhe. Observe o FAILURE status de cada teste.
memtester version 4.5.1 (64-bit)
Copyright (C) 2001-2020 Charles Cazabon.
Licensed under the GNU General Public License version 2 (only).
pagesize is 4096
pagesizemask is 0xfffffffffffff000
want 1024MB (1073741824 bytes)
got 1024MB (1073741824 bytes), trying mlock ...locked.
Loop 1/5:
Stuck Address : testing 1FAILURE: possible bad address line at offset 0x25378a58.
Skipping to next test...
Random Value : FAILURE: 0x4df704aaafdf8848 != 0x4df704aaafdfc848 at offset 0x05379a48.
Compare XOR : ok
Compare SUB : ok
Compare MUL : ok
Compare DIV : ok
Compare OR : ok
Compare AND : ok
Sequential Increment: ok
Solid Bits : testing 6FAILURE: 0x00000000 != 0x00004000 at offset 0x05379a48.
Block Sequential : testing 3FAILURE: 0x303030303030303 != 0x303030303034303 at offset 0x05379a48.
Checkerboard : testing 0FAILURE: 0xaaaaaaaaaaaaaaaa != 0xaaaaaaaaaaaaeaaa at offset 0x05379a48.
Bit Spread : testing 12FAILURE: 0xffffffffffffafff != 0xffffffffffffefff at offset 0x05379a48.
Bit Flip : testing 0FAILURE: 0x00000001 != 0x00004001 at offset 0x05379a48.
Walking Ones : ok
Walking Zeroes : testing 0FAILURE: 0x00000001 != 0x00001001 at offset 0x053af9f8.
8-bit Writes : -FAILURE: 0x57c7c8ba7d6f5b3b != 0x57c7c8ba7d6f1b3b at offset 0x0537da28.
16-bit Writes : -FAILURE: 0xd7768894fbf79099 != 0xd7768894fbf7d099 at offset 0x05379a48.
FAILURE: 0xfffc5633ffefca5d != 0xfffc5633ffefda5d at offset 0x053a5a38.
.
.
.
Se os erros persistirem em todos os loops de teste, isso sugere fortemente problemas de hardware, não falhas temporárias de software.
8.10.2 Identificando problemas de superaquecimento
O superaquecimento pode causar erros e travamentos inesperados. Para diagnosticar problemas de superaquecimento, você pode usar um utilitário de linha de comando lm-sensors.
lm-sensors Permite monitorar a integridade do hardware lendo dados de vários sensores. Ele fornece informações sobre temperaturas do sistema, tensões e velocidades das ventoinhas.
Veja como você pode identificar e monitorar a temperatura do seu sistema usando lm-sensors:
-
Primeiro, instale
lm-sensors:sudo apt install lm-sensors -
Detecte os sensores disponíveis no seu sistema:
sudo sensors-detectSiga as instruções e responda “SIM” para detectar os sensores disponíveis no seu sistema.
-
Depois que os sensores disponíveis forem detectados, você pode visualizar a temperatura do seu sistema usando o
sensorscomando:sensorsNa saída abaixo, você pode ver a leitura de temperatura na borda da GPU, que é de 41,0 graus Celsius. Você também pode ver outras informações, como tensão fornecida, consumo de energia e tensão fornecida.
amdgpu-pci-0400 Adapter: PCI adapter vddgfx: 731.00 mV vddnb: 687.00 mV edge: +41.0°C PPT: 7.00 WO uso
lm-sensorsgarante que o sistema esteja operando dentro de parâmetros seguros. Ajuda a detectar possíveis problemas de hardware precocemente e a tomar medidas corretivas para evitar danos ao hardware.
8.10.3 Avaliação da integridade do disco rígido
Erros de disco também podem causar travamentos de aplicativos. Para identificar problemas de disco, você pode executar uma verificação de disco usando smartmontools:
-
Primeiro, instale
smartmontools:sudo apt install smartmontools -
Execute uma verificação rápida de integridade usando o comando abaixo e substitua
/dev/sdXpelo nome do seu disco (marque comlsblk).sudo smartctl -H /dev/sdX -
Aqui está o resultado que obtive quando executei o comando no meu disco
/dev/nvme0n1:sudo smartctl -H /dev/nvme0n1 smartctl 7.4 2023-08-01 r5530 [x86_64-linux-6.8.0-52-generic] (local build) Copyright (C) 2002-23, Bruce Allen, Christian Franke, www.smartmontools.org === START OF SMART DATA SECTION === SMART overall-health self-assessment test result: PASSED -
Você também pode executar um teste detalhado:
sudo smartctl -a /dev/nvme0n1
O teste detalhado fornece um relatório completo, incluindo:
-
Temperatura
-
Horas de funcionamento
-
Contagens de erros
-
Nivelamento de desgaste (para SSDs) e muito mais.
8.10.4 Realizando um teste de estresse da CPU
CPUs defeituosas também podem causar uma série de problemas de desempenho. Para testar sua CPU, você pode usar o stress-ng utilitário:
-
Instalar
stress-ng:sudo apt install stress-ng -
Execute um teste de estresse da CPU:
stress-ng --cpu 4 --timeout 60
No comando acima, 4 é o número de núcleos de CPU que você gostaria de testar e 60 a duração em segundos. O comando sobrecarregará todos os 4 núcleos de CPU por 60 segundos. Observe que a CPU está em 100% carga durante o teste:

Se o sistema travar durante este teste, a CPU pode estar com defeito.
8.10.5 Examinando logs do sistema em busca de erros
systemd é um gerenciador de sistema Linux responsável por inicializar o sistema, gerenciar processos do sistema e manipular serviços do sistema.
journalctl é um comando para consultar os systemd logs do diário. Ele fornece registros detalhados de processos do sistema, eventos do kernel, aplicativos do usuário e muito mais.
Você pode verificar os logs do sistema para erros relacionados ao hardware usando o comando: journalctl -k | grep -iE "error|fault|panic".
Nos logs, procure mensagens sobre:
-
Falhas de memória.
-
Erros de E/S.
-
Tempo limite de hardware.
Veja como os erros no arquivo de log podem se parecer:
Feb 11 10:15:32 hostname kernel: [Hardware Error]: CPU 0: Machine Check: 0 Bank 4: b200000000070f0f
Feb 11 10:15:32 hostname kernel: [Hardware Error]: TSC 0 ADDR fef1c000 MISC 38a0000086
Feb 11 10:15:32 hostname kernel: [Hardware Error]: PROCESSOR 0:306a9 TIME 1613045732 SOCKET 0 APIC 0 microcode 1f
Feb 11 10:16:45 hostname kernel: EXT4-fs error (device sda1): ext4_find_entry:1453: inode #2: comm ls: reading directory lblock 0
Feb 11 10:17:12 hostname kernel: [drm:drm_atomic_helper_commit_cleanup_done [drm_kms_helper]] *ERROR* [CRTC:36:pipe A] flip_done timed out
Feb 11 10:18:05 hostname kernel: Kernel panic - not syncing: Fatal exception
Conclusão
Obrigado por ler o livro até o final. Se você achou útil, considere compartilhá-lo com outras pessoas