
Olá, pessoal! 👋 No final das contas, aprendi sobre Node.js. Então, decida compartilhar meus aprendizados com vocês aqui. 👨💻
Neste tutorial, daremos uma olhada geral no Node.js: o que é e o que você pode fazer com ele.
Abordaremos todos os conceitos importantes do Node com exemplos práticos e muitos trechos de código. Isso lhe dará o conhecimento básico necessário para começar a desenvolver backend com NodeJS.
Veja o que abordaremos neste guia:
- O que é NodeJS?
- Variáveis Globais
- Módulos
- Nota curta sobre
module.exports - Tipos de Módulos
- Programação orientada a eventos
- Criando nosso primeiro servidor
- Vamos servir algo interessante!
- Conclusão
O que é Node?
O Node é um ambiente no qual você pode executar o código JavaScript " fora do navegador ". O Node funciona como: "Ei, pessoal, me deem o código JS e eu o executeei 😎". Ele usa o mecanismo V8 do Google para converter o código JavaScript em código de máquina.
Como o Node executa o código JavaScript fora do navegador da web, isso significa que ele não tem acesso a certos recursos que estão disponíveis apenas no navegador, como o DOM, o windowobjeto ou mesmo o localStorage.
Isso significa que em nenhum ponto do seu código você pode digitar, document.querySelector()pois alert()isso produzirá erros (mostrado na imagem abaixo).
Lembre-se: o Node é destinado à programação do lado do servidor, enquanto os recursos do navegador são destinados à programação do lado do cliente.

Pessoal do front-end, não fique triste – ainda há mais! O Node oferece diversas APIs e módulos com os quais você pode uma variedade de operações, como manipulação de arquivos, criação de servidores e muito mais. Antes de mergulhar no NodeJS, vamos colocá-lo em nossa máquina.
Como instalar o NodeJS
Instalar o NodeJS é simples. Se você já tem o NodeJS instalado em sua máquina, pode pular esta seção. Caso contrário, siga em frente.
Aqui estão os passos para baixar o NodeJS em sua máquina:
- Navegue até https://nodejs.org/
- Baixe a versão LTS do NodeJS para seu sistema operacional
- Execute o instalador e siga o assistente de instalação. Basta responder "Sim" a todas as perguntas.
- Após a conclusão da instalação, abra um novo terminal ou janela de prompt de comando e execute o seguinte comando para verificar se o NodeJS está instalado corretamente:
node -v. Se a versão do NodeJS for exibida no seu terminal, parabéns! Você instalou o NodeJS com sucesso na sua máquina.
Observação: se você encontrar algum problema durante o processo de instalação, consulte a documentação oficial do NodeJS para obter instruções mais detalhadas e dicas de solução de problemas.
Variáveis Globais
Vamos começar este artigo aprendendo sobre algumas variáveis presentes no NodeJS, chamadas Variáveis Globais. São basicamente variáveis que armazenam dados e podem ser acessadas de qualquer lugar do seu código – não importa quão profundamente aninhado ele esteja.
Você deve conhecer estas variáveis globais comumente usadas:
__dirname: Esta variável armazena o caminho para o diretório de trabalho atual.__filename: Esta variável armazena o caminho para o arquivo de trabalho atual.
Vamos usá-los e ver o valor que eles contêm. Para isso, vamos criar uma nova pasta chamada NodeJSTut "e" Desktop e abri-la com seu editor de texto favorito (em todo o tutorial, usaremos o VS Code). Crie um novo arquivo chamado "e" app.js e abra um novo terminal integrado do VS Code.
Cole o seguinte código no app.js arquivo e salve-o:
// __dirname Global Variable
console.log(__dirname);
// __filename Global Variable
console.log(__filename);
Para executar este código usando o Node, digite o seguinte comando no terminal e pressione Enter: node app.js. Você verá o caminho absoluto para o diretório de trabalho atual e o caminho para o arquivo atual será exibido no terminal. A saída no meu caso é a seguinte:
C:DesktopNodeJSTut
C:DesktopNodeJSTutapp.js
Você pode criar suas próprias variáveis globais, que podem ser acessadas de qualquer lugar do seu código. Você pode fazer isso assim:
// Define a global variable in NodeJS
global.myVariable = 'Hello World';
// Access the global variable
console.log(myVariable); // Output: Hello World
Módulos em NodeJS
Em Node.js, um módulo é essencialmente um bloco de código reutilizável que pode ser usado para executar um conjunto específico de tarefas ou fornecer uma funcionalidade específica. Um módulo pode conter variáveis, funções, classes, objetos ou qualquer outro código que possa ser usado para realizar uma tarefa ou conjunto de tarefas específico.
O principal objetivo do uso de módulos no Node.js é ajudar a organizar o código em partes menores e mais fáceis de gerenciar. Os módulos podem ser importados a qualquer momento e usados com flexibilidade, o que ajuda a criar componentes de código reutilizáveis que podem ser compartilhados entre vários projetos.
Para entender isso, considere este exemplo: digamos que você definiu muitas funções em seu código que funcionam com um grande volume de dados JSON.
Perder o sono e aumentar os níveis de ansiedade são efeitos colaterais comuns de manter tudo isso (funções + dados + alguma outra lógica) em um único arquivo.
Então você, sendo um programador inteligente, pensou em criar um arquivo separado para os dados JSON e um arquivo separado para armazenar todas as funções. Agora, você pode simplesmente importar os dados e as funções quando quiser e usá-los conforme necessário. Esse método aumenta a eficiência, pois o tamanho do arquivo é reduzido drasticamente. Este é o conceito de módulos!
Vamos ver como podemos criar nossos próprios módulos. Para isso, vamos escrever um código onde definiremos uma função chamada sayHello() em um arquivo chamado hello.js. Essa função aceitará a name como parâmetro e simplesmente exibirá uma mensagem de saudação no console.
Em seguida, importaremos para outro arquivo chamado app.js e o usaremos lá. Que interessante, não é mesmo? 😂 Vamos conferir o código:
Este é o código no hello.js arquivo:
function sayHello(name){
console.log(`Hello ${name}`);
}
module.exports = sayHello
Este é o código no app.js arquivo:
const sayHello = require('./hello.js');
sayHello('John');
sayHello('Peter');
sayHello('Rohit');
O arquivo hello.js pode ser chamado de module neste caso. Cada módulo possui um objeto chamado exports , que deve conter tudo o que você deseja exportar deste módulo, como variáveis ou funções. No nosso caso, estamos definindo uma função no hello.js arquivo e exportando-a diretamente.
O app.js arquivo importa a sayHello() função hello.js e a armazena na sayHello variável. Para importar algo de um módulo, usamos o require() método que aceita o caminho para o módulo. Agora, podemos simplesmente invocar a variável e passar um nome como parâmetro. Executar o código no app.js arquivo produzirá a seguinte saída:
Hello John
Hello Peter
Hello Rohit
Nota curta sobre module.exports
Na seção anterior do artigo, vimos como usar, module.exports mas achei importante entender como funciona com mais detalhes. Portanto, esta seção do artigo é como um minitutorial, onde veremos como exportar uma variável/função, bem como múltiplas variáveis e funções usando module.exports. Então, vamos começar:
module.exports é um objeto especial em NodeJS que permite exportar funções, objetos ou valores de um módulo, para que outros módulos possam acessá-los e utilizá-los. Aqui está um exemplo de como module.exports exportar uma função de um módulo:
// myModule.js
function myFunction() {
console.log('Hello from myFunction!');
}
module.exports = myFunction;
Neste exemplo, definimos uma função myFunction e a exportamos usando module.exports. Outros módulos agora podem exigir este módulo e usar a função exportada:
// app.js
const myFunction = require('./myModule');
myFunction(); // logs 'Hello from myFunction!'
Tudo parece bem agora e a vida está indo bem. Mas o problema surge quando precisamos exportar várias funções e variáveis de um único arquivo. O problema é que, ao usar module.exports várias vezes um único módulo, ele substituirá o valor atribuído anteriormente pelo novo. Considere este código:
// module.js
function myFunction() {
console.log('Hello from myFunction!');
}
function myFunction2() {
console.log('Hello from myFunction2!');
}
// First Export
module.exports = myFunction;
// Second Export
module.exports = myFunction2;
Neste exemplo, primeiro exportamos myFunction(). Mas então sobrescrevemos module.exports com uma nova função - myFunction2(). Como resultado, apenas a segunda instrução export entrará em vigor, e a myFunction() função não será exportada.
Esse problema pode ser resolvido se você atribuir module.exports a um objeto que contém todas as funções que deseja exportar, assim:
// myModule.js
function myFunction1() {
console.log('Hello from myFunction1!');
}
function myFunction2() {
console.log('Hello from myFunction2!');
}
module.exports = {
foo: 'bar',
myFunction1: myFunction1,
myFunction2: myFunction2
};
Neste exemplo, exportamos um objeto com três propriedades: foo, myFunction1e myFunction2. Outros módulos podem exigir este módulo e acessar estas propriedades:
// app.js
const myModule = require('./myModule');
console.log(myModule.foo); // logs 'bar'
myModule.myFunction1(); // logs 'Hello from myFunction1!'
myModule.myFunction2(); // logs 'Hello from myFunction2!'
Resumindo, você pode usar module.exports quantas vezes quiser no seu código NodeJS, mas esteja ciente de que cada nova atribuição substituirá a anterior. Você deve usar um objeto para agrupar várias exportações.
Tipos de módulos no Node
Existem 2 tipos de módulos no NodeJS:
- Módulos Integrados : São módulos incluídos no Node por padrão, então você pode usá-los sem instalação. Basta importá-los e começar.
- Módulos Externos : São módulos criados por outros desenvolvedores que não são incluídos por padrão. Portanto, você precisa instalá-los antes de usá-los.
Aqui está uma imagem de módulos integrados populares no NodeJS e o que você pode fazer usando-os:

Vamos analisar cada um deles com mais detalhes para que você possa aprender mais sobre o que eles fazem.
O módulo do sistema operacional
O Módulo SO (como o próprio nome indica) fornece métodos/funções com os quais você pode obter informações sobre seu Sistema Operacional.
Para usar este módulo, o primeiro passo é importá-lo assim:
const os = require('os');
É assim que você pode usar o Módulo OS para obter informações sobre o Sistema Operacional:👇
const os = require('os')
// os.uptime()
const systemUptime = os.uptime();
// os.userInfo()
const userInfo = os.userInfo();
// We will store some other information about my WindowsOS in this object:
const otherInfo = {
name: os.type(),
release: os.release(),
totalMem: os.totalmem(),
freeMem: os.freemem(),
}
// Let's Check The Results:
console.log(systemUptime);
console.log(userInfo);
console.log(otherInfo);
Esta é a saída do código acima:
Observe que a saída mostra informações sobre o sistema operacional Windows em execução no meu sistema. A saída pode ser diferente da sua.
521105
{
uid: -1,
gid: -1,
username: 'krish',
homedir: 'C:Userskrish',
shell: null
}
{
name: 'Windows_NT',
release: '10.0.22621',
totalMem: 8215212032,
freeMem: 1082208256
}
Vamos analisar o código acima e a saída:
os.uptime()informa o tempo de atividade do sistema em segundos. Esta função retorna o número de segundos em que o sistema está em execução desde a última reinicialização. Se você verificar a primeira linha da saída:521105é o número de segundos, meu sistema está em execução desde a última reinicialização. Claro, será diferente para você.os.userInfo()fornece informações sobre o usuário atual. Esta função retorna um objeto com informações sobre o usuário atual, incluindo o ID do usuário, o ID do grupo, o nome de usuário, o diretório inicial e o shell padrão. Abaixo está o detalhamento da saída no meu caso:
{
uid: -1,
gid: -1,
username: 'krish',
homedir: 'C:Userskrish',
shell: null
}
O uid e gid está definido como -1 no Windows porque o Windows não possui o conceito de IDs de usuário como os sistemas baseados em Unix. O username do meu sistema operacional é krish e o diretório inicial é 'C:Userskrish'. O shell está definido como null porque o conceito de shell padrão não existe no Windows. O Windows tem um programa interpretador de comandos padrão chamado Prompt de Comando (cmd.exe), que executa comandos e gerencia o sistema.
Os outros métodos relacionados ao Módulo do SO, como os.type(), os.release() e assim por diante, que você viu no código acima, foram usados dentro do otherInfo objeto. Aqui está uma análise do que esses métodos fazem:
os.type()- Informa o nome do Sistema Operacionalos.release()- Informa a versão de lançamento do Sistema Operacionalos.totalMem()- Informa a quantidade total de memória disponível em bytesos.freeMem()- Informa a quantidade total de memória livre disponível em bytes
Estas são as informações que os métodos acima exibem sobre meu sistema operacional:
{
name: 'WindowsNT', // Name of my OS
release: '10.0.22621', // Release Version of my OS
totalMem: 8215212032, // Total Memory Available in bytes (~ 8 GB)
freeMem: 1082208256 // Free Memory Available in bytes (~ 1 GB)
}
O Módulo PATH
O módulo PATH é útil ao trabalhar com caminhos de arquivos e diretórios. Ele fornece vários métodos com os quais você pode:
- Unir segmentos de caminho
- Diga se um caminho é absoluto ou não
- Obter a última parte/segmento de um caminho
- Obtenha a extensão do arquivo de um caminho e muito mais!
Você pode ver o módulo PATH na ação no código abaixo.
Código:
// Import 'path' module using the 'require()' method:
const path = require('path')
// Assigning a path to the myPath variable
const myPath = '/mnt/c/Desktop/NodeJSTut/app.js'
const pathInfo = {
fileName: path.basename(myPath),
folderName: path.dirname(myPath),
fileExtension: path.extname(myPath),
absoluteOrNot: path.isAbsolute(myPath),
detailInfo: path.parse(myPath),
}
// Let's See The Results:
console.log(pathInfo);
Saída:
{
fileName: 'app.js',
folderName: '/mnt/c/Desktop/NodeJSTut',
fileExtension: '.js',
absoluteOrNot: true,
detailInfo: {
root: '/',
dir: '/mnt/c/Desktop/NodeJSTut',
base: 'app.js',
ext: '.js',
name: 'app'
}
}
Vamos analisar detalhadamente o código acima e sua saída:
O primeiro e mais importante passo para trabalhar com patho módulo é importá-lo para o app.jsarquivo usando o require()método .
Em seguida, atribuímos o caminho de um arquivo a uma variável chamada myPath. Este pode ser um caminho para qualquer arquivo aleatório. Para entender o pathmódulo, escolhi isto: /mnt/c/Desktop/NodeJSTut/app.js.
Usando uma myPathvariável, entenderemos o pathmódulo em detalhes. Vamos conferir as funções que este módulo oferece e o que podemos fazer com ele:
path.basename(myPath): Abasename()função aceita um caminho e retorna a última parte desse caminho. No nosso caso, a última partemyPathé:app.js.path.dirname(myPath): Adirname()função seleciona a última parte do caminho fornecido e retorna o caminho para o diretório pai. No nosso caso, como a última parte demyPathéapp.js. Adirname()função retorna o caminho para o diretório pai deapp.js(a pasta dentro de qualapp.jso arquivo está), ou seja,/mnt/c/Desktop/NodeJSTut. Também pode ser pensado como: adirname()função simplesmente excluir a última parte do caminho fornecido e retornar o caminho restante.path.extname(myPath): Esta função verifica se há alguma extensão na última parte do caminho fornecido e retorna a extensão do arquivo (se existir); caso contrário, retorna uma string vazia:''. No nosso caso, como a última parte éapp.jse existe uma extensão de arquivo, obtemos'.js'como saída.path.isAbsolute(myPath): Isso indica se o caminho fornecido é absoluto ou não. Em sistemas baseados em Unix (como macOS e Linux), um caminho absoluto sempre começa com uma barra (/). Em sistemas Windows, um caminho absoluto pode começar com uma letra de unidade (comoC:) seguida por dois pontos (:), ou com duas barras invertidas (). Como o valor armazenado namyPathvariável começa com/,isAbsolute()retornatrue.
Entretanto, se você apenas alterar a myPathvariável para isto: Desktop/NodeJSTut/app.js(convertendo-a em um caminho relativo), isAbsolute()retorna false.
path.parse(myPath): Esta função aceita um caminho e retorna um objeto que contém uma análise detalhada do caminho fornecido. Aqui está o que ela retorna quando fornece umamyPathvariável:root: A raiz do caminho (neste caso,/).dir: O diretório do arquivo (neste caso,/mnt/c/Desktop/NodeJSTut).base: O nome do arquivo base (neste caso,app.js).ext: A extensão do arquivo (neste caso,.js).name: O nome base do arquivo, sem a extensão (neste caso,app).
Antes de continuar com as outras funções do pathmódulo, precisamos entender algo chamado separador de caminho e a estrutura de caminho .
Você deve ter notado que o caminho para um mesmo arquivo é diferente em diferentes sistemas operacionais. Por exemplo, considere o caminho para um arquivo chamado example.txtlocalizado em uma pasta chamada Documentsna área de trabalho de um usuário do Windows:
C:UsersusernameDesktopDocumentsxample.txt
Por outro lado, o caminho do arquivo para o mesmo arquivo para um usuário em um sistema macOS ficaria assim:
/Users/username/Desktop/Documents/example.txt
Duas diferenças devem ser vistas aqui:
- Diferença entre separadores de caminho: No Windows, os caminhos de arquivo usam a barra invertida (
) como separador entre diretórios, enquanto no macOS/Linux (que é um sistema baseado em Unix), os caminhos de arquivo usam a barra normal (/) como separador. - Diferença no diretório raiz dos arquivos do usuário: No Windows, o diretório raiz dos arquivos do usuário é comumente encontrado em
C:Usersusername, enquanto no macOS e Linux, ele está localizado em/Users/username/. Embora seja válido para a maioria dos sistemas Windows, macOS e Linux, pode haver algumas variações na localização exata do diretório inicial do usuário com base na configuração do sistema.
Com isso em mente, vamos obrigar e entender algumas outras funções disponibilizadas pelo pathmódulo:
path.sep:sepé uma variável que contém o separador de caminho específico do sistema. Para máquinas Windows:console.log(path.sep)imprimeno console, enquanto no caso de macOS ou Linux,path.sepretorna uma barra (/).path.join(<paths>): Apath.join()função aceita caminhos como strings. Em seguida, ela percorre esses caminhos usando o separador de caminho específico do sistema e retorna o caminho unido. Por exemplo, considere este código:
console.log(path.join('grandParentFolder', 'parentFolder', 'child.txt'))
O código acima imprime resultados diferentes para diferentes sistemas operacionais.
No Windows, ele retornará esta saída: grandParentFolderparentFolderchild.txtenquanto no macOS/Linux, ele retornará esta saída: grandParentFolder/parentFolder/child.txt. Observe que a diferença está apenas nos separadores de caminho — barra invertida e barra normal.
path.resolve(<paths>): Esta função funciona de forma semelhante apath.join(). Apath.resolve()função apenas é um dos diferentes caminhos fornecidos a ela usando o separador de caminho específico do sistema e, em seguida, anexa a saída final ao caminho absoluto do diretório de trabalho atual.
Suponha que você seja um usuário do Windows e o caminho absoluto para seu diretório de trabalho atual seja este: C:DesktopNodeJSTut. Se você executar este código:
console.log(path.resolve('grandParentFolder', 'parentFolder', 'child.txt'));
Você verá a seguinte saída no console:
C:DesktopNodeJSTutgrandParentFolderparentFolderchild.txt
O mesmo se aplica a usuários de macOS ou Linux. A única diferença é que não há caminho absoluto do diretório de trabalho atual e não há separador de caminho.
O Módulo FS
Este módulo ajuda você com operações de arquivos complementares como:
- Lendo um arquivo (de forma síncrona ou assíncrona)
- Escrevendo em um arquivo (de forma síncrona ou assíncrona)
- Excluindo um arquivo
- Lendo o conteúdo de um diretor
- Renomeando um arquivo
- Observar alterações em um arquivo e muito mais
Vamos executar algumas dessas tarefas para ver o fsmódulo (Sistema de Arquivos) na ação abaixo:
Como criar um diretório usandofs.mkdir()
A fs.mkdir()função em Node.js é usada para criar um novo diretório. Ela recebe dois argumentos: o caminho do diretório a ser criado e uma função de retorno de chamada opcional que é realizada quando a operação é concluída.
- caminho : Aqui, caminho se refere ao local onde você deseja criar uma nova pasta. Este pode ser um caminho absoluto ou relativo. No meu caso, o caminho para o diretório de trabalho atual (a pasta em que estou atualmente) é:
C:DesktopNodeJSTut. Então, vamos criar uma pasta noNodeJSTutdiretório chamadamyFolder. - Função de retorno de chamada: O objetivo da função de retorno de chamada é notificar que o processo de criação do diretório foi concluído. Isso é necessário porque a
fs.mkdir()função é assíncrona, o que significa que ela não bloqueia a execução do restante do código enquanto a operação está em andamento. Em vez disso, ela retorna imediatamente o controle para a função de retorno de chamada, permitindo que ela continue executando outras tarefas. Após a criação do diretório, a função de retorno de chamada é chamada com um objeto de erro (se houver) e quaisquer outros dados relevantes relacionados à operação. No código abaixo, estamos apenas usando-o para exibir uma mensagem de sucesso no console ou qualquer erro.
// Import fs module
const fs = require('fs');
// Present Working Directory: C:DesktopNodeJSTut
// Making a new directory called ./myFolder:
fs.mkdir('./myFolder', (err) => {
if(err){
console.log(err);
} else{
console.log('Folder Created Successfully');
}
})
Depois de executar o código acima, você verá uma nova pasta myFoldercriada no NodeJSTutdiretório.
Como criar e gravar em um arquivo de forma sincronizada usandofs.writeFile()
Depois que o myFolderdiretório for criado com sucesso, é hora de criar um arquivo e escrever algo nele usando o fsmódulo.
Existem basicamente duas maneiras de fazer isso:
- Abordagem Síncrona: Nesta abordagem, criamos um arquivo e gravamos os dados nele de forma bloqueada, o que significa que o NodeJS aguarda a conclusão da operação de criação e gravação antes de passar para a próxima linha de código. Se ocorrer um erro durante esse processo, ele gera uma exceção que deve ser capturada usando
try...catch. - Abordagem Assíncrona: Nesta abordagem, criamos e gravamos dados em um arquivo de forma não bloqueante, o que significa que o NodeJS não espera a conclusão da operação de gravação antes de passar para a próxima linha de código. Em vez disso, ele utiliza uma função de retorno de chamada que é chamada assim que todo o processo é concluído. Se ocorrer um erro durante uma operação de gravação, o objeto de erro foi passado para a função de retorno de chamada.
Neste tutorial, usaremos a fs.writeFile()função que segue a abordagem assíncrona.
writeFile()é um método fornecido pelo fsmódulo (sistema de arquivos) em Node.js. Ele é usado para gravar dados em um arquivo de forma sincronizada. O método obtém três argumentos:
- O caminho do arquivo a ser gravado (incluindo o nome e a extensão do arquivo)
- Os dados a serem gravados no arquivo (como uma string ou buffer)
- Uma função de retorno de chamada opcional que é chamada quando a operação de gravação é concluída ou ocorre um erro durante a operação de gravação.
Quando writeFile() é chamado, o Node.js cria um novo arquivo ou sobrescreve um arquivo existente no caminho especificado . Em seguida, ele grava os dados fornecidos no arquivo e o fecha. Como o método é assíncrono, a operação de gravação não bloqueia o loop de eventos, permitindo que outras operações sejam realizadas nesse meio tempo.
Abaixo está o código onde criamos um novo arquivo chamado myFile.txt no myFolder diretório e escrevemos isto data nele: Hi,this is newFile.txt.
const fs = require('fs');
const data = "Hi,this is newFile.txt";
fs.writeFile('./myFolder/myFile.txt', data, (err)=> {
if(err){
console.log(err);
return;
} else {
console.log('Writen to file successfully!');
}
})
Como newFile.txt não existia anteriormente, a writeFile() função criou este arquivo para nós no caminho fornecido e, em seguida, gravou o valor da data variável no arquivo. Suponha que este arquivo já existisse. Nesse caso, writeFile() bastará abrir o arquivo, apagar todo o texto existente nele e gravar os dados nele.
O problema com esse código é: quando você executa o mesmo código várias vezes, ele apaga os dados anteriores que já estavam presentes newFile.txt e grava os dados nele.
Caso você não queira que os dados originais sejam excluídos e queira apenas que os novos dados sejam adicionados/anexados ao final do arquivo, você precisa fazer uma pequena alteração no código acima adicionando este "objeto de opções": {flag: 'a'} como o terceiro parâmetro writeFile() – assim:
const fs = require('fs');
const data = 'Hi,this is newFile.txt';
fs.writeFile('./myFolder/myFile.txt', data, {flag: 'a'}, (err) => {
if(err){
console.log(err);
return;
} else {
console.log('Writen to file successfully!');
}
})
Ao executar o código acima repetidamente, você verá que myFile.txt o valor da data variável é escrito várias vezes. Isso ocorre porque o objeto (3º parâmetro): {flag: 'a'} indica o writeFile() método para anexar o data ao final do arquivo em vez de apagar os dados anteriores presentes nele.
Como ler um arquivo de forma assíncrona usando fs.readFile()
Depois de criar e gravar no arquivo, é hora de aprender a ler os dados presentes no arquivo usando o fs módulo.
Novamente, há duas maneiras de fazer isso: a abordagem síncrona e a abordagem assíncrona (assim como a função anterior). Aqui, usaremos a readFile() função fornecida pelo fs módulo, que realiza a operação de leitura de forma assíncrona.
A readFile() função recebe 3 parâmetros:
- O caminho para o arquivo que deve ser lido.
- A codificação do arquivo.
- A função de retorno de chamada é executada assim que a operação de leitura é concluída ou se ocorrer algum erro durante a operação. Ela aceita 2 parâmetros: o primeiro parâmetro armazena os dados do arquivo (se a operação de leitura for bem-sucedida) e o segundo parâmetro armazena o objeto de erro (se a operação de leitura falhar devido a algum erro).
A readFile() função é muito intuitiva e, uma vez chamada, lê os dados presentes no arquivo fornecido de acordo com a codificação fornecida. Se a operação de leitura for bem-sucedida, ela retorna os dados para a função de retorno de chamada e, caso contrário, retorna o erro ocorrido.
No código abaixo, lemos o conteúdo do arquivo - myFile.txt que criamos enquanto aprendíamos a função anterior - e então registramos os dados armazenados nele no console.
const fs = require('fs');
fs.readFile('./myFolder/myFile.txt', {encoding: 'utf-8'}, (err, data) => {
if(err){
console.log(err);
return;
} else {
console.log('File read successfully! Here is the data');
console.log(data);
}
})
É importante notar aqui que a encoding propriedade está definida como 'utf-8'. Neste ponto, alguns de vocês podem não saber sobre a propriedade de codificação. Então, vamos entendê-la com mais detalhes:
O encoding parâmetro no fs.readFile() método do Node.js é usado para especificar a codificação de caracteres usada para interpretar os dados do arquivo. Por padrão, se nenhum encoding parâmetro for fornecido, o método retorna um buffer bruto.
Se o readFile() método for chamado sem fornecer um encoding parâmetro, você verá um resultado semelhante a este impresso no console:
<Buffer 54 68 69 73 20 69 73 20 73 6f 6d 65 20 64 61 74 61 20 69 6e 20 61 20 66 69 6c 65>
Este buffer bruto é difícil de ler e interpretar, pois representa o conteúdo do arquivo em formato binário. Para converter o buffer em uma string legível, você pode especificar um encoding parâmetro ao chamar readFile().
No nosso caso, especificamos a 'utf8' codificação como o segundo parâmetro do readFile() método. Isso instrui o Node.js a interpretar o conteúdo do arquivo como uma string usando a codificação de caracteres UTF-8, permitindo que você veja os dados originais impressos no console. Outras codificações comuns que podem ser usadas readFile() incluem:
'ascii': Interpretar o conteúdo do arquivo como texto codificado em ASCII.'utf16le': Interprete o conteúdo do arquivo como texto Unicode de 16 bits em ordem de bytes little-endian.'latin1': Interprete o conteúdo do arquivo como texto codificado em ISO-8859-1 (também conhecido como Latin-1).
Lendo e escrevendo em um arquivo de forma sincronizada
Até agora, você aprendeu como gravar e ler dados de um arquivo de forma assíncrona. Mas existem alternativas síncronas para as duas funções que aprendemos acima, a saber: readFileSync() e writeFileSync().
Observe que, como essas operações são síncronas, elas precisam ser encapsuladas em um try...catch bloco. Caso as operações falhem por algum motivo, os erros gerados serão capturados pelo catch bloco.
No código abaixo, primeiro criamos um novo arquivo: ./myFolder/myFileSync.txt e escrevemos nele usando o writeFileSync() método . Em seguida, lemos o conteúdo do arquivo usando o readFileSync() método e imprimimos os dados no console:
const fs = require('fs');
try{
// Write to file synchronously
fs.writeFileSync('./myFolder/myFileSync.txt', 'myFileSync says Hi');
console.log('Write operation successful');
// Read file synchronously
const fileData = fs.readFileSync('./myFolder/myFileSync.txt', 'utf-8');
console.log('Read operation successful. Here is the data:');
console.log(fileData);
} catch(err){
console.log('Error occurred!');
console.log(err);
}
Ao executar o código acima, um novo arquivo chamado myFileSync.txt é criado no myFolder diretório e contém o seguinte texto: myFileSync says Hi. Esta é a saída impressa no console:
Write operation successful
Read operation successful. Here is the data:
myFileSync says Hi
Como ler o conteúdo de um diretório usando fs.readdir()
Se você acompanhou até agora, verá que atualmente temos dois arquivos no myFolderdiretório, ou seja, myFile.txte myFileSync.txt. O fsmódulo fornece uma readdir()função para que você possa ler o conteúdo de um diretório (os arquivos e pastas presentes no diretório).
A readdir()função aceita 2 parâmetros:
- O caminho da pasta cujo conteúdo deve ser lido.
- Função de retorno de chamada que é realizada assim que a operação é concluída ou ocorre algum erro durante a operação. Esta função aceita 2 parâmetros: o primeiro, que aceita o objeto de erro (se ocorrer algum erro), e o segundo, que aceita uma matriz dos vários arquivos e pastas presentes no diretório cujo caminho foi fornecido.
No código abaixo, estamos lendo o conteúdo do myFolderdiretório e imprimindo o resultado no console.
const fs = require('fs');
fs.readdir('./myFolder', (err, files) => {
if(err){
console.log(err);
return;
}
console.log('Directory read successfully! Here are the files:');
console.log(files);
})
Isto é o que obtemos como saída quando executamos o código acima:
[ 'myFile.txt', 'myFileSync.txt' ]
Como renomear um arquivo usandofs.rename()
O fs.rename()método em Node.js é usado para renomear um arquivo ou diretório. O método recebe dois argumentos: o caminho do arquivo atual e o novo caminho do arquivo, além de uma função de retorno de chamada que é realizada quando a renomeação é concluída.
Aqui está a sintaxe do fs.rename()método:
fs.rename(oldPath, newPath, callback);
onde:
oldPath(string) - O caminho do arquivo atualnewPath(string) - O novo caminho do arquivocallback(função) - Uma função de retorno de chamada a ser realizada quando a renomeação for concluída. Esta função recebe um objeto de erro como único parâmetro.
Vamos renomear o newFile.txtarquivo para newFileAsync.txt:
const fs = require('fs');
fs.rename('./newFolder/newFile.txt', './newFolder/newFileAsync.txt', (err)=>{
if(err){
console.log(err);
return;
}
console.log('File renamed successfully!')
})
Depois de executar o código acima, você verá que o newFile.txtserá renomeado para newFileAsync.txt.
Observe que você deve fornecer apenas caminhos válidos (absolutos ou relativos) para a rename()função e não apenas os nomes dos arquivos. Lembre-se de que é oldPathe newPathe NÃO oldNamee newName.
Por exemplo, considere este código: fs.rename('./newFolder/newFile.txt', 'newFileAsync.txt', ...rest of the code). Neste caso, como não fornece um caminho protegido no segundo parâmetro, rename()assuma que o caminho para o arquivo recém-nomeado deve ser: ./newFileAsync.txt. Assim, ele basicamente remove o newFile.txtdiretório newFolder, renomeia o arquivo para newFileAsync.txte move para o diretório de trabalho atual.
Como excluir um arquivo usandofs.unlink()
Por último, mas não menos importante, temos a fs.unlink()função usada para excluir um arquivo. Ela recebe 2 parâmetros:
- O caminho do arquivo que você deseja excluir e
- Uma função de retorno de chamada que é executada quando uma operação de exclusão termina ou ocorre algum erro durante a operação.
A execução do código a seguir exclui o newFileSync.txtarquivo presente no myFolderdiretório:
const fs = require('fs');
fs.unlink('./myFolder/myFileSync.txt', (err) => {
if(err){
console.log(err);
return;
}
console.log('File Deleted Successfully!')
})
Programação orientada a eventos
Ok, antes de obrigarmos a aprender o Módulo HTTP e criar nossos próprios servidores, é importante conhecer algo chamado "programação orientada a eventos".
A programação orientada a eventos é um paradigma de programação em que o fluxo do programa é amplamente determinado por eventos ou ações do usuário, e não pela lógica do programa.
Nesse tipo de programação, o programa de escuta de eventos e, quando eles ocorrerem, ele executa algum código/função que deve ser executado em resposta a esse evento.
Um evento pode ser qualquer coisa, desde um clique do mouse ou um pressionamento de botão até a chegada de novos dados no sistema.
A imagem abaixo demonstra como funciona a programação orientada a eventos. Nessa forma de programação, escrevemos um código que monitora constantemente um evento específico e, quando esse evento ocorre, executamos um código em resposta a ele.
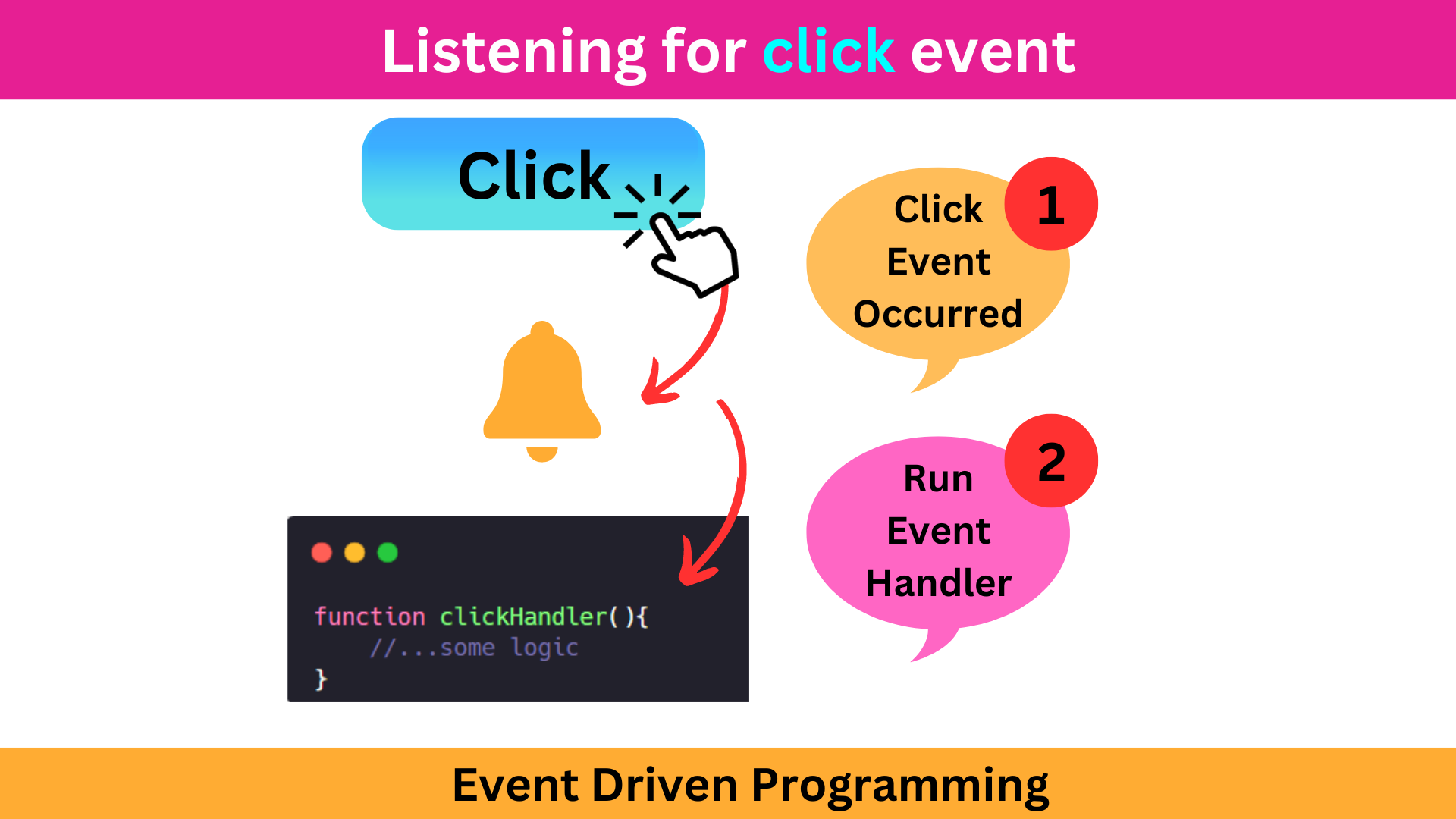
Nesta seção do tutorial, aprenderemos sobre eventos em NodeJS. Embora possamos não usar eventos diretamente em nossas tarefas diárias de programação, muitos módulos NodeJS utilizam o conceito de eventos internamente. Por isso, é importante estar ciente disso.
Para implementar uma Programação Orientada para Eventos no NodeJS, você precisa se lembrar de duas coisas:
-
Existe uma função chamada
emit()que faz com que um evento ocorra.
Por exemplo,emit('myEvent')emite/causa um evento chamadomyEvent. -
Existe outra função chamada
on()que é usada para escutar um evento específico e, quando esse evento ocorre, oon()método executa uma função de escuta em resposta a ele. Por exemplo, considere este código:on('myEvent', myFunction)Aqui, estamos escutando um evento chamadomyEvente, quando esse evento ocorrer, executamos amyFunctionfunção de escuta em resposta a ele.
Podemos acessar as on()funções emit()e criar uma instância da EventEmitteraula. A EventEmitterclasse pode ser importada de um pacote integrado chamado events.
No código abaixo, estamos ouvindo o userJoinedevento e, quando esse evento ocorre, executamos a welcomeUser()função usando o on()método e emitimos o userJoinedevento usando o emit()método:
// Importing 'events' module and creating an instance of the EventEmitter Class
const EventEmitter = require('events');
const myEmitter = new EventEmitter();
// Listener Function - welcomeUser()
const welcomeUser = () => {
console.log('Hi There, Welcome to the server!');
}
// Listening for the userJoined event using the on() method
myEmitter.on('userJoined', welcomeUser);
// Emitting the userJoined event using the emit() method
myEmitter.emit('userJoined');
Pontos a serem observados:
Há 3 pontos que você deve observar ao trabalhar com eventos no Node.
Cada ponto é marcado em ação nos trechos de código correspondentes:
- Pode haver vários
on()para um únicoemit():
Veja o código a seguir, onde diversas on()funções estão escutando um único evento acontecido ( userJoinedevento) e quando esse evento é emitido na última linha do código usando a emit()função, você verá que todas as funções de escuta que foram anexadas à on()função são executadas:
// Importing `events` module and creating an instance of EventEmitter class
const EventEmitter = require('events');
const myEmitter = new EventEmitter();
// Listener Function 1: sayHello
const sayHello = () => {
console.log('Hello User');
}
// Listener Function 2: sayHi
const sayHi = () => {
console.log('Hi User');
}
// Listener Function 3: greetNewYear
const greetNewYear = () => {
console.log('Happy New Year!');
}
// Subscribing to `userJoined` event
myEmitter.on('userJoined', sayHello);
myEmitter.on('userJoined', sayHi);
myEmitter.on('userJoined', greetNewYear);
// Emiting the `userJoined` Event
myEmitter.emit('userJoined');
Você pode pensar desta forma: cada vez que o userJoinedevento é emitido, uma notificação é enviada a todas as on()funções que escutam o evento e então todas elas executam suas funções de escuta correspondentes: sayHello, sayHi, greetNewYear.
Portanto, ao executar o código, você verá a seguinte saída impressa no console:
Hello User
Hi User
Happy New Year!
- O
emit()também pode conter argumentos que serão passados para as funções de escuta:
No código a seguir, estamos usando o on()método para distribuir um evento chamado birthdayEvente, quando esse evento for emitido, executamos a greetBirthday()função em resposta a ele.
As configurações extras recomendadas na emit()função são passadas como configurações para todas as funções dos ouvintes que serão executadas em resposta a birthdayEvent. Portanto John, e 24são passadas como parâmetros para a greetBirthday()função.
const EventEmitter = require('events');
const myEvent = new EventEmitter();
// Listener function
const greetBirthday = (name, newAge) => {
// name = John
// newAge = 24
console.log(`Happy Birthday ${name}. You are now {newAge}!`);
}
// Listening for the birthdayEvent
myEmitter.on('birthdayEvent', greetBirthday);
// Emitting the birthdayEvent with some extra parameters
myEmitter.emit('birthdayEvent', 'John', '24');
A seguinte saída será impressa no console: Happy Birthday John, You are now 24!.
- A
emit()função deve sempre ser definida após aon()(s) função(ões):
Todo o processo de comunicação entre on()e emit()funciona assim: antes de emitir qualquer evento, você precisa garantir que todas as funções dos ouvintes estejam inscritas/registradas naquele evento. Qualquer função registrada como ouvinte após a remessa do evento não será realizada.
Veja o código a seguir onde esse processo é treinado em detalhes:
const EventEmitter = require('events');
const myEmitter = new EventEmitter();
// Listener Function 1 - sayHi
const sayHi = () => {
console.log('Hi User');
}
// Listener Function 2 - sayHello
const sayHello = () => {
console.log('Hello User');
}
// Registering sayHi function as listener
myEmitter.on('userJoined', sayHi);
// Emitting the event
myEmitter.emit('userJoined');
// Registering sayHello function as listener
myEmitter.on('userJoined', sayHello);
Quando o código acima é executado, vemos Hi Userimpresso no console, mas Hello Usernão é impresso.
O motivo disso é: primeiro, registramos a sayHifunção como ouvinte usando myEmitter.on('userJoined', sayHi). Em seguida, emitimos o userJoinedevento que resulta na execução da sayHifunção. Na próxima linha, estamos registrando a sayHellofunção como ouvinte, mas já é tarde demais para fazer isso, pois userJoinedo evento já foi emitido. Isso demonstra a importância de definir todas as on()funções antes de emitirmos o evento usando emit().
Você também pode pensar desta forma: quando você usa o método emit()para disparar um evento, o NodeJS procura por quaisquer on()métodos correspondentes que tenham sido definidos no seu código acima do emit()método. Se encontrar algum, ele o executará para tratar o evento.
O módulo HTTP
Vamos seguir em frente e aprender o Módulo HTTP que ajuda você a criar Servidores Web.
HTTP significa Protocolo de Transferência de Hipertexto. É usado para transferir dados pela internet, permitindo a comunicação entre clientes e servidores.
Suponha que você queira assistir alguns vídeos do YouTube. Você acessa seu navegador e digital: https://youtube.com . A página inicial do YouTube é exibida na tela. Todo esse processo ocorre devido à comunicação entre sua máquina (cliente) e o servidor do YouTube. O cliente, neste caso, sua máquina, solicita a página inicial do YouTube e o servidor envia os arquivos HTML, CSS e JS como resposta.
O cliente envia uma solicitação ao servidor na forma de uma URL com algumas informações adicionais, como cabeçalhos e parâmetros de consulta.
O servidor processa a solicitação, executa as operações necessárias e envia uma resposta ao cliente. A resposta contém um código de status, cabeçalhos e o corpo da resposta com os dados solicitados.
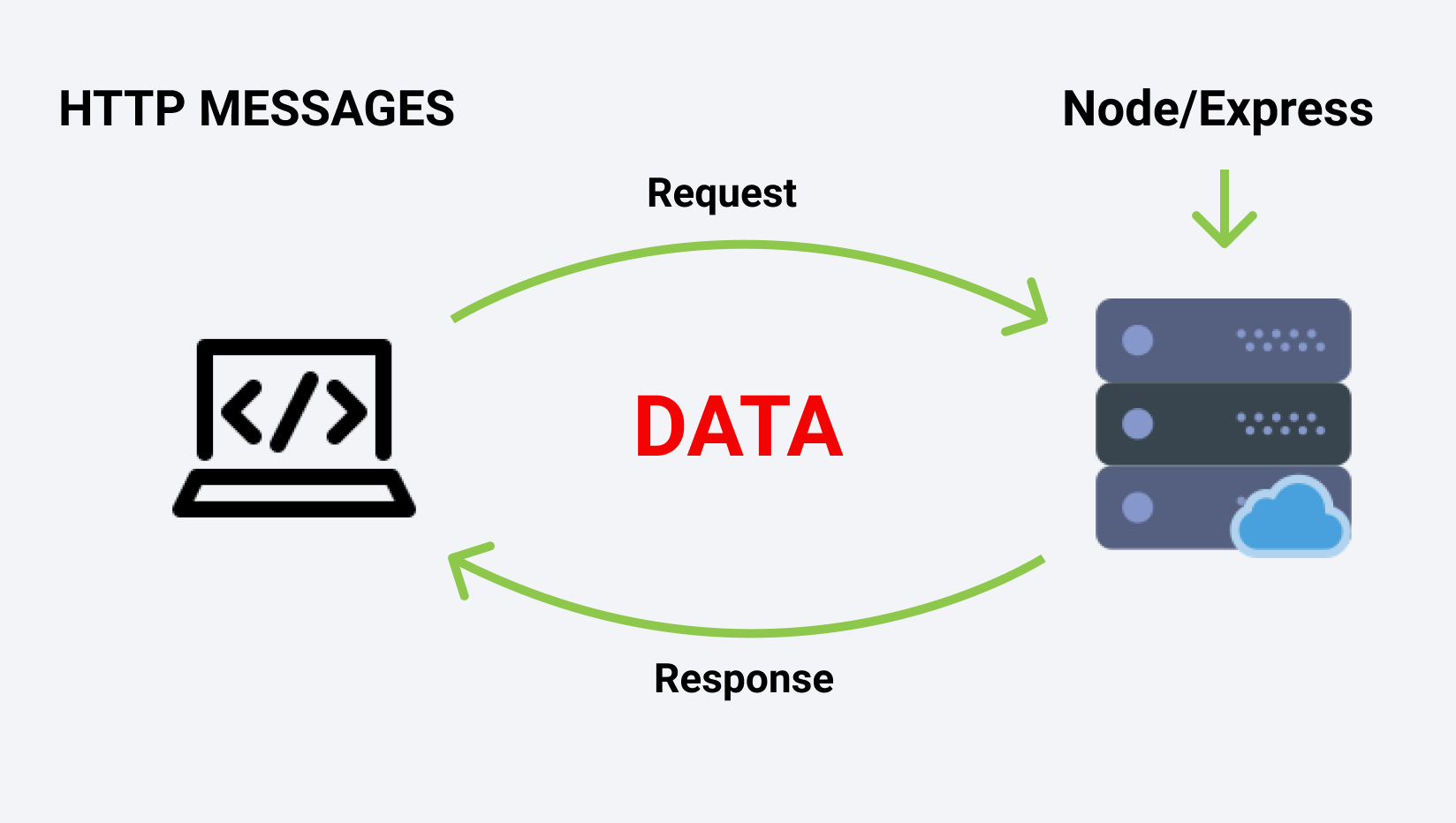 _ Fonte: https://course-api.com/slides/ _
_ Fonte: https://course-api.com/slides/ _
Componentes da solicitação-resposta
Tanto a Solicitação (enviada pelo cliente ao servidor) quanto a Resposta (enviada pelo servidor ao cliente) são compostas de 3 partes:
- Linha de Status : Esta é a primeira linha de solicitação ou resposta. Ela contém informações sobre a mensagem, como o método utilizado, URL, versão do protocolo e assim por diante.
- O Cabeçalho : É uma coleção de pares de chave-valor, separados por dois pontos.
Os cabeçalhos incluem informações adicionais sobre a mensagem, como tipo de conteúdo, tamanho do conteúdo, informações de cache e assim por diante. - Corpo : O corpo contém os dados enviados ou recebidos. No caso de interferência, pode conter dados de formulário ou configurações de consulta. No caso de respostas, pode ser HTML, JSON, XML ou qualquer outro formato de dados.
Os 3 componentes de uma Solicitação e Resposta são descritos com muito mais detalhes na imagem abaixo:
 _ Fonte: https://course-api.com/slides/ _
_ Fonte: https://course-api.com/slides/ _
O que são métodos HTTP?
Métodos HTTP, também conhecidos como verbos HTTP, são ações que um Cliente pode executar em um Servidor. Os 4 métodos HTTP são:
- GET: Recupera um recurso do servidor
- POST: Insira um recurso no servidor
- PUT: Atualiza um recurso existente no servidor
- DELETE: Exclui um recurso do servidor
Isso pode parecer complicado, mas vamos tentar entender esses métodos com a ajuda de um exemplo:
- GET: Recupera um recurso do servidor.
Quando você digitahttp://www.google.comna barra de endereço do seu navegador e pressiona Enter, o navegador envia uma solicitação HTTP GET ao servidor do Google solicitando o conteúdo HTML da página inicial do Google. Este é então renderizado e exibido pelo seu navegador. - POST : Insere um recurso no servidor.
Imagine que você está preenchendo um formulário de cadastro para criar uma conta no Google. Ao enviar o formulário, seu navegador envia uma solicitação POST ao servidor do Google com os dados que você digitou nos campos do formulário, como: nome de usuário, idade, data de nascimento, endereço, número de telefone, e-mail, sexo e assim por diante.
O servidor criará então uma nova conta de usuário em seu banco de dados, armazenando todas as informações enviadas a ele por meio da solicitação POST. Assim, uma solicitação POST é usada para adicionar/inserir um recurso no servidor.
- PUT : Atualiza um recurso existente no servidor.
Agora imagine que você queira atualizar a senha da sua conta do Google. Você enviaria uma solicitação PUT ao servidor com uma nova senha. O servidor então atualizaria sua conta de usuário no banco de dados com uma nova senha. - DELETE : Exclui um recurso do servidor.
Por fim, imagine que você deseja excluir sua conta de usuário do Google. Você enviaria uma solicitação DELETE ao servidor interromper que deseja que sua conta seja restauração. O servidor então excluiria sua conta de usuário do banco de dados.
Observe que estes são apenas exemplos. As obrigações reais e suas finalidades podem variar.
Para ver mais exemplos de métodos HTTP, você pode consultar esta imagem:
 _ Fonte: https://course-api.com/slides/ _
_ Fonte: https://course-api.com/slides/ _
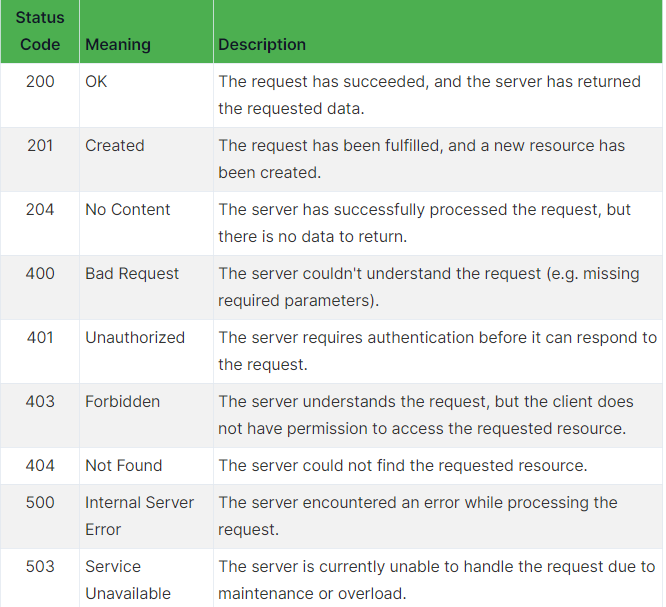
O que é um código de status?
Os códigos de status HTTP são números de três dígitos que indicam o status de uma solicitação HTTP feita a um servidor. São respostas do servidor que fornecem informações sobre o resultado da solicitação. Aqui estão alguns dos códigos de status HTTP mais comuns e o que eles representam:
Vamos criar um servidor
Por fim, vamos para a parte boa 🥳🔥 e aprender como criar um Servidor Web usando o httpmódulo:
Etapa 1: importe o httpmódulo assim:
const http = require('http');
Etapa 2: O httpmódulo fornece uma http.createServer()função que ajuda a criar um servidor. Esta função aceita uma função de retorno de chamada com 2 parâmetros – req(que armazena o objeto de solicitação recebida) e resque representa a resposta a ser enviada pelo servidor. Esta função de retorno de chamada é executada sempre que alguém acessa o servidor.
É assim que podemos criar um servidor usando a createServer()função:
const http = require('http');
const server = http.createServer((req, res) => {
res.end('Hello World');
})
Observação: res.send()é uma função anexada ao resobjeto, com a qual podemos enviar alguns dados de volta ao cliente. Assim que terminarmos de configurar o servidor, você verá uma Hello Worldmensagem no seu navegador.
Etapa 3: Ouvir o servidor em alguma porta usando o listen()método.
A listen()função no httpmódulo Node.js é usada para iniciar um servidor que recebe comunicações recebidas. Ela recebe um número de porta como argumento e vincula o servidor a esse número de porta para que ele possa receber reclamações recebidas nessa porta.
No código abaixo, use a listen()função para iniciar o servidor e vinculá-lo à porta 5000. O segundo argumento da listen()função é uma função de retorno de chamada que é executada quando o servidor começa a escutar na porta especificada. Estamos usando essa função de retorno de chamada apenas para exibir uma mensagem de sucesso no console.
const http = require('http');
const server = http.createServer((req, res) => {
res.end('Hello World');
})
server.listen(5000, () => {
console.log('Server listening at port 5000');
})
É provável que você veja uma Hello Worldmensagem ao visitar este URL: http://localhost:5000/ .

Se você tentar acessar outra porta, como 5001 ( http://localhost:5001/ ), que não esteja vinculado ao seu servidor, não verá nenhuma resposta porque o servidor não está escutando essa porta. Você provavelmente receberá uma mensagem de erro informando que a conexão com o servidor não poderia ser estabelecida.
Neste ponto, criamos um servidor que exibe uma Hello World mensagem simples sempre que alguém tenta acessá-lo. Isso é muito bom, mas há um problema...
O problema é que, para cada rota, o servidor envia a mesma mensagem. Por exemplo, se eu tentar acessar a página "Sobre" ou a página de contato, o servidor ainda mostra a mesma mensagem:
- http://localhost:5000/ -> Olá Mundo
- http://localhost:5000/about -> Olá Mundo
- http://localhost:5000/contact -> Olá Mundo
Há uma maneira simples de corrigir isso: há uma propriedade chamada urlno reqobjeto que fornece uma URL da solicitação ou, em outras palavras, informações sobre o recurso que o cliente está tentando acessar.
Suponha que eu digite: http://localhost:5000/about na barra de pesquisa do meu navegador. Isso significa que estou realizando uma solicitação GET no servidor e tentando acessar uma /aboutpágina. Portanto, neste caso, o valor de req.urlserá /about.
Da mesma forma, para as obrigações abaixo, o valor de req.urlserá:
| URL | req.url |
|---|---|
| http://localhost:5000 | / |
| http://localhost:5000/sobre | /about |
| http://localhost:5000/contato | /contact |
| http://localhost:5000/erro | /error |
Podemos usar algumas condicionais if...elsejunto com a req.urlpropriedade para fazer com que nosso servidor responda a diferentes solicitações de forma diferente. Veja como podemos fazer isso:
const http = require('http');
const server = http.createServer((req, res) => {
if(req.url === '/'){
res.end('This is my Home Page');
} else if(req.url === '/about'){
res.end('This is my About Page');
} else if(req.url === '/contact'){
res.end('This is my Contact Page');
} else {
res.end('404, Resource Not Found');
}
})
server.listen(5000, () => {
console.log('Server listening at port 5000');
})
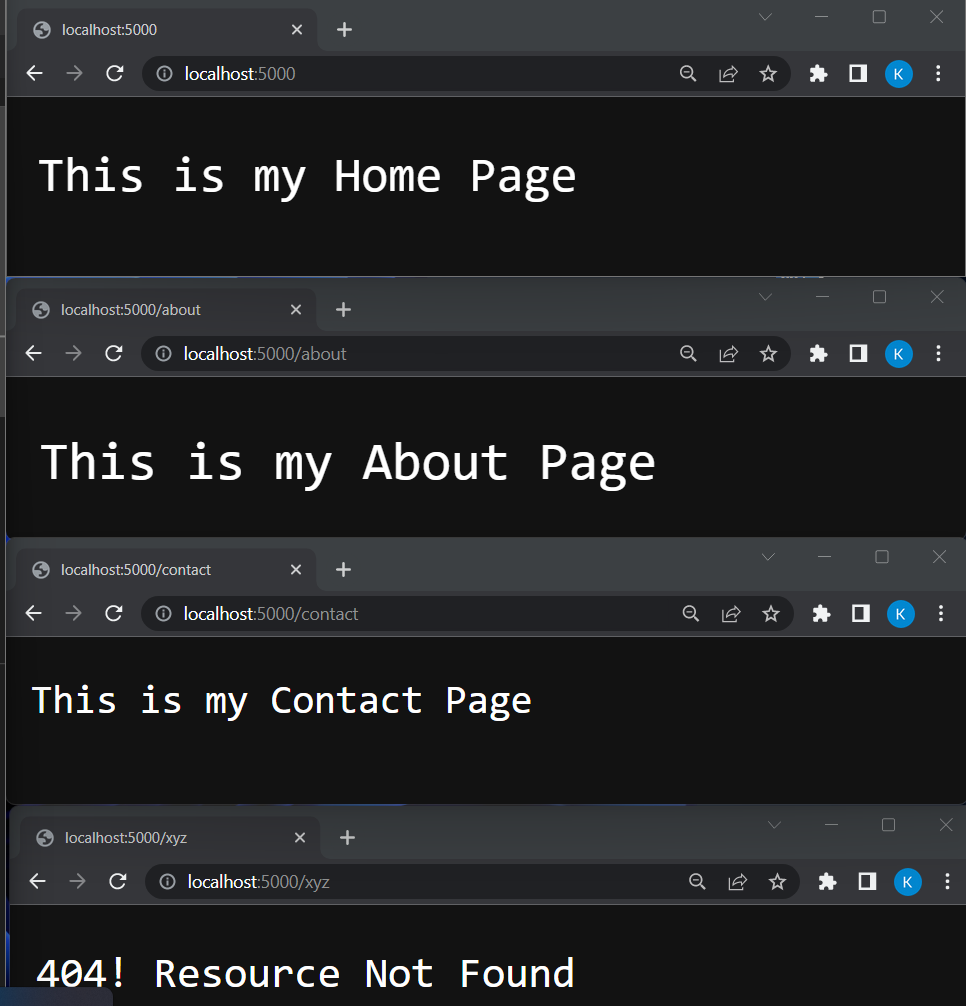
Agora temos um servidor perfeito que responde a diferentes interfaces de forma diferente. Estamos enviando respostas usando um método chamado res.end(). Mas existe uma maneira ainda melhor de enviar uma resposta, na qual podemos adicionar mais dois métodos, além de res.end():
res.writeHead()– Este método é usado para enviar os cabeçalhos de resposta ao cliente. O código de status e cabeçalhos semelhantescontent-typepodem ser definidos usando este método.res.write()– Este método é usado para enviar o corpo da resposta ao cliente.res.end()– Este método é usado para finalizar o processo de resposta.
Abaixo está o código modificado onde adicionamos os métodos writeHead()e write()junto com end()o método:
const http = require('http');
const server = http.createServer((req, res) => {
if(req.url === '/'){
res.writeHead(200, {'content-type': 'text/html'});
res.write('<h1>Home Page</h1>');
res.end();
} else if(req.url === '/about'){
res.writeHead(200, {'content-type': 'text/html'});
res.write('<h1>About Page</h1>');
res.end();
} else if(req.url === '/contact'){
res.writeHead(200, {'content-type': 'text/html'});
res.write('<h1>Contact Page</h1>');
res.end();
} else {
res.writeHead(404, {'content-type': 'text/html'});
res.write('<h1>404, Resource Not Found <a href="/">Go Back Home</a></h1>');
res.end();
}
})
server.listen(5000, () => {
console.log('Server listening at port 5000');
})
A imagem abaixo mostra o que o servidor envia como resposta quando visitamos vários URLs:

Vamos analisar o que está acontecendo no código acima:
- Aqui estamos respondendo de forma diferente a diferentes recebimentos usando um
req.urlpropriedade. - Em cada resposta, fazemos 3 coisas:
– Definindo o cabeçalho da resposta usando ores.writeHead()método . Aqui, fornecemos 2 parâmetros parares.writeHead(): o código de status e um objeto com acontent-typepropriedade definida comotext/html
– Definindo o corpo da resposta usando ores.write()método . Observe que, em vez de enviar mensagens simples, estamos, na verdade, enviando algum código HTML neste caso,
– E encerrando o processo de resposta usando ores.end()método . - No caso de recursos como:
/,/abouto/contactcódigo de status é definido como ,200o que significa que uma solicitação de acesso a um recurso foi bem-sucedida. Mas se o cliente tentar acessar outro recurso, ele simplesmente receberá uma mensagem de erro e o código de status será definido como404. - Aqui
'content-type': 'text/html'está uma maneira de informar ao navegador como ele deve interpretar e exibir uma resposta. Neste caso, estamos falando ao navegador para interpretar a resposta como um código HTML. Existem diferentescontent-type's' para diferentes tipos de resposta:
– Para enviar dados JSON como resposta, precisamos definir ocontent-typetoapplication/json
– Para enviar CSS como resposta, ocontent-typedeveria sertext/css
– Para enviar código JavaScript como resposta, ocontent-typedeveria sertext/javascripte assim por diante...
Definir o tipo de conteúdo é muito importante, pois determina como o navegador interpreta a resposta. Por exemplo: se apenas alterarmos o tipo de conteúdo do parágrafo text/html, text/plainuma resposta será exibida no navegador da web da seguinte forma:
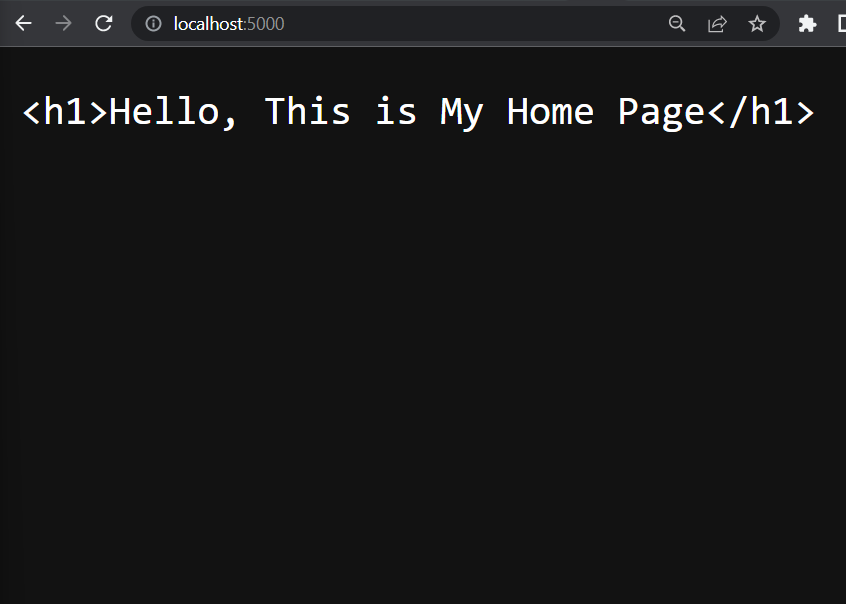
Vamos servir algo interessante
Até agora você aprendeu a configurar servidores web, mas não construímos nada interessante. Então, vamos adicionar um pouco de diversão às nossas vidas.
Na última seção deste tutorial, serviremos esta barra de navegação:
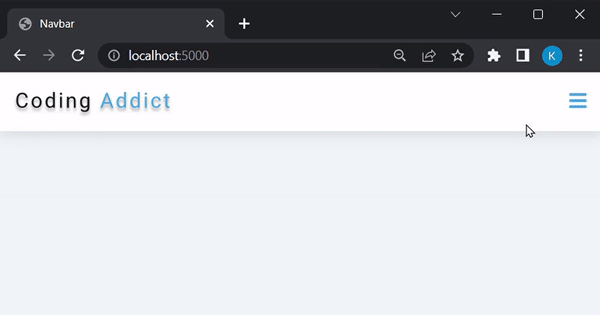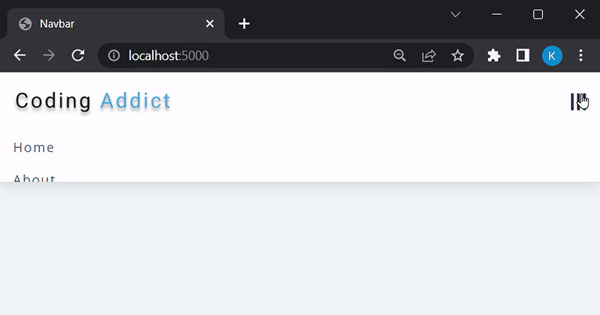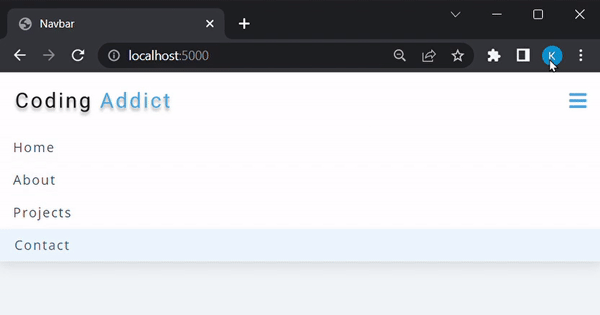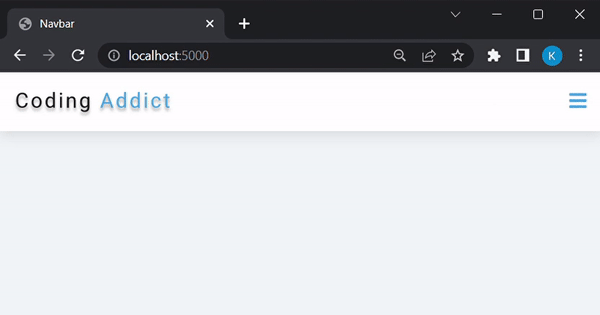
Como este não é um tutorial relacionado a front-end, não criaremos esta barra de navegação do zero. Em vez disso, você pode acessar este repositório do GitHub, copiar o conteúdo do navbar-appdiretório e configurá-lo localmente: repositório do GitHub de John Smilga . A ideia é:
- Configurar um
navbar-apppasta localmente - Usar o
fsmódulo para ler o conteúdo do arquivo HTML, CSS, JS e do logotipo - Usando o
httpmódulo para renderizar os arquivos quando alguém tenta acessar a/rota ou a página inicial. Então, vamos começar:
No código abaixo, estamos usando o método fsdo módulo readFileSync() para ler o conteúdo do arquivo HTML, CSS, JS e do logotipo.
Observe que vamos servir o conteúdo do arquivo e não o arquivo em si. Então readFileSync() entre em cena.
Em seguida, servimos o conteúdo do arquivo HTML (armazenado na homePagevariável) usando o res.write()método . Lembre-se de definir o content-typeque, text/htmlpois estamos dentro do conteúdo HTML. Também configuramos respostas para /abouta rota e uma página 404.
const http = require('http');
const fs = require('fs');
// Get the contents of the HTML, CSS, JS and Logo files
const homePage = fs.readFileSync('./navbar-app/index.html');
const homeStyles = fs.readFileSync('./navbar-app/style.css');
const homeLogo = fs.readFileSync('./navbar-app/logo.svg');
const homeLogic = fs.readFileSync('./navbar-app/browser-app.js');
// Creating the Server
const server = http.createServer((req, res) => {
const url = req.url;
if(url === '/'){
res.writeHead(200, {'content-type': 'text/html'});
res.write(homePage);
res.end();
} else if(url === '/about'){
res.writeHead(200, {'content-type': 'text/html'});
res.write(<h1>About Page</h1>);
res.end();
} else{
res.writeHead(200, {'content-type': 'text/html'});
res.write(<h1>404, Resource Not Found</h1>);
res.end();
}
})
server.listen(5000, () => {
console.log('Server listening at port 5000');
})
Ao executar este código usando node app.jso comando, você verá estas respostas enviadas pelo servidor para as seguintes rotas:
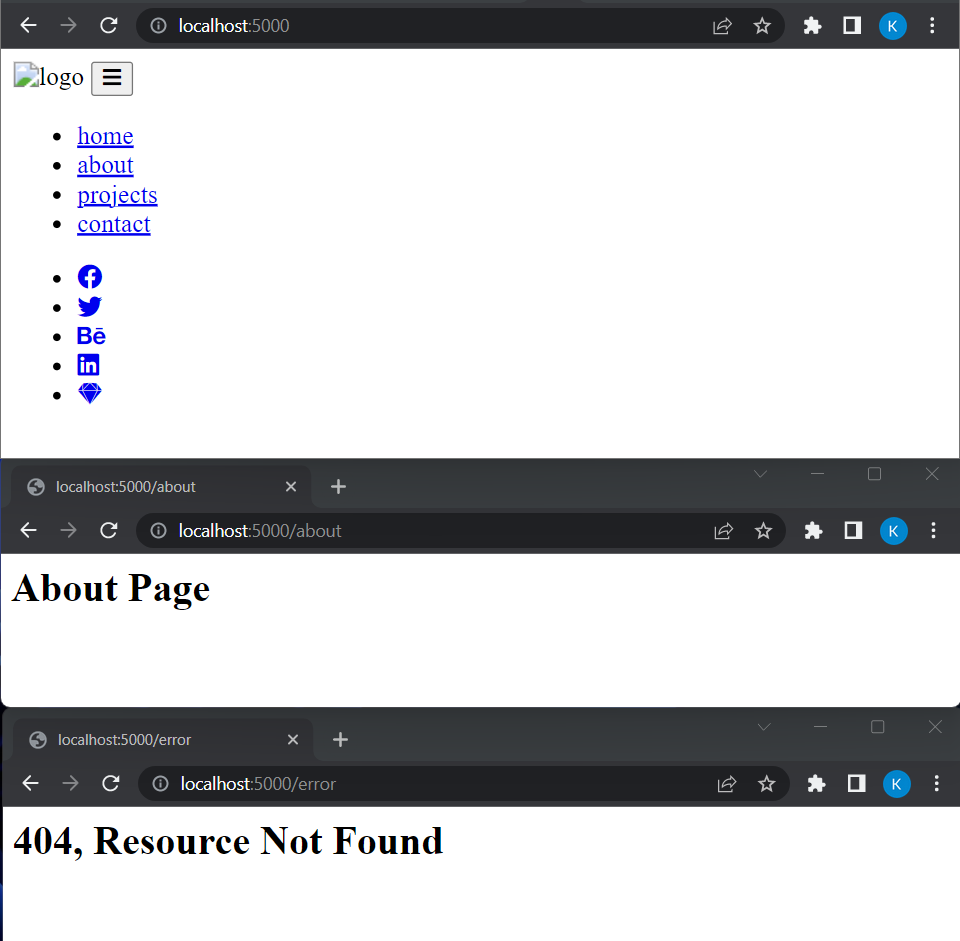
Vemos que as outras rotas funcionam bem, mas a página inicial não tem a aparência esperada. O problema é que vemos apenas a estrutura HTML da barra de navegação sendo exibida e não os outros elementos, como CSS, logotipo e JavaScript.
Vamos ver qual é o bug. Podemos verificar quais requisições estão sendo feitas pelo navegador ao servidor modificando o código acima desta forma:
// ... above code
const server = http.createServer((req, res) => {
const url = req.url;
console.log(url);
// ... rest of the code
})
Aqui estamos simplesmente imprimindo urla solicitação feita pelo cliente ao servidor.
Ao atualizar a página, vemos que inicialmente o navegador solicita uma página inicial e faz uma solicitação GET com uma /URL. Em seguida, ele faz mais 3 desvantagens:
/style.css– pedindo o arquivo CSS/browser-app.js– pedindo o arquivo JS/logo.svg– pedindo o logotipo
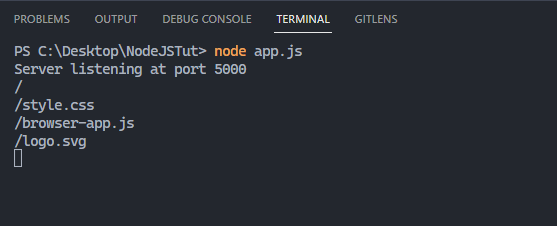
A partir disso, podemos inferir como os navegadores funcionam.
O navegador solicita o conteúdo do /caminho e do servidor apenas envia de volta o conteúdo HTML. Assim que o navegador recebe o conteúdo HTML, ele o interpreta e começa a exibir os elementos. Ao analisar HTML, se o navegador encontrar algum recurso adicional, como uma página CSS ou JS, ele fará uma solicitação ao servidor.
Como não estamos enviando CSS, JS e logotipo na resposta, não os vemos na tela. Podemos corrigir isso adicionando mais alguns if()no código e enviando os recursos que o navegador solicita e BOOM – esse bug foi corrigido.
const http = require('http');
const fs = require('fs');
// Get the contents of the HTML, CSS, JS and Logo files
const homePage = fs.readFileSync('./navbar-app/index.html');
const homeStyles = fs.readFileSync('./navbar-app/style.css');
const homeLogo = fs.readFileSync('./navbar-app/logo.svg');
const homeLogic = fs.readFileSync('./navbar-app/browser-app.js');
// Creating the Server
const server = http.createServer((req, res) => {
const url = req.url;
if(url === '/'){
res.writeHead(200, {'content-type': 'text/html'});
res.write(homePage);
res.end();
} else if(url === '/style.css'){
res.writeHead(200, {'content-type': 'text/css'});
res.write(homeStyles);
res.end();
} else if(url === '/browser-app.js'){
res.writeHead(200, {'content-type': 'text/javascript'});
res.write(homeLogic);
res.end();
} else if(url === '/logo.svg'){
res.writeHead(200, {'content-type': 'image/svg+xml'});
res.write(homeLogo);
res.end();
} else if(url === '/about'){
res.writeHead(200, {'content-type': 'text/html'});
res.write(<h1>About Page</h1>);
res.end();
} else{
res.writeHead(200, {'content-type': 'text/html'});
res.write(<h1>404, Resource Not Found</h1>);
res.end();
}
})
server.listen(5000, () => {
console.log('Server listening at port 5000');
})
Agora podemos ver o HTML, CSS, Logotipo e a Funcionalidade JS presentes:

Conclusão
Com isso chegamos ao final deste tutorial – espero que você tenha gostado e aprendido bastante sobre o Node